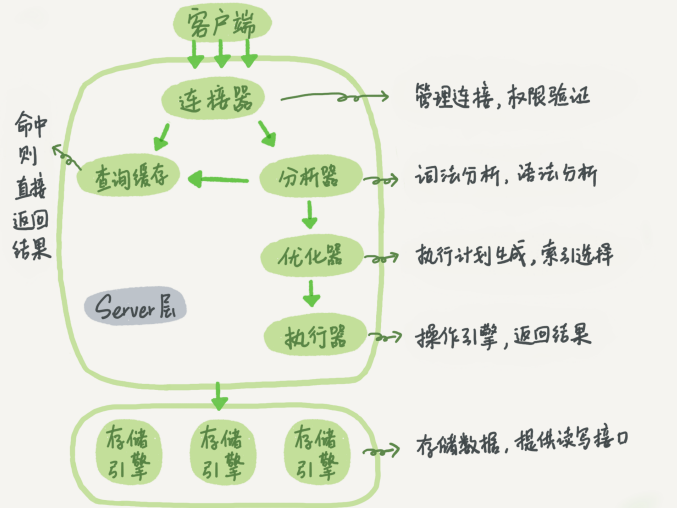
首先,查询语句的那一套流程,更新语句也是同样会走一遍。与查询流程不一样的是,更新流程还涉及两个重要的日志模块,它们正是我们今天要讨论的主角:redo log(重做日志)和 binlog(归档日志)。
1. redo log
在 MySQL 中,为了避免每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新导致整个过程 IO 成本、查找成本过高。MySQL 会先数据库操作先存储在日志中再写磁盘来提升更新效率(WAL 技术,全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘)。
具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log 里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做。
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。