1. 脑裂现象
所谓的脑裂,就是指在主从集群中,同时有两个主节点,它们都能接收写请求。而脑裂最直接的影响,就是客户端不知道应该往哪个主节点写入数据,结果就是不同的客户端会往不同的主节点上写入数据。而且,严重的话,脑裂会进一步导致数据丢失。
哨兵(sentinel)模式下的脑裂:
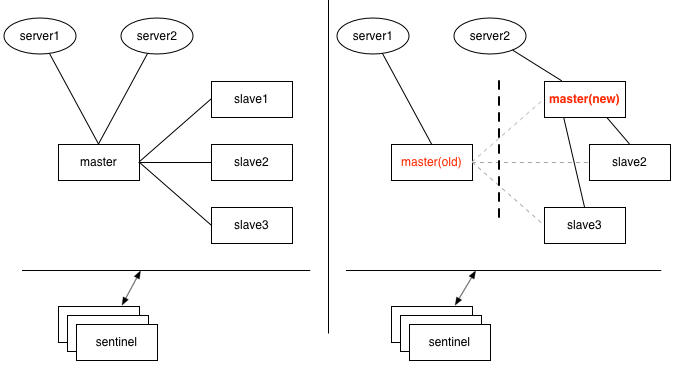
如上图,1 个 master 与 3 个 slave 组成的哨兵模式(哨兵独立部署于其它机器),刚开始时,2 个应用服务器 server1、server2 都连接在 master上,如果 master 与 slave 及哨兵之间的网络发生故障,但是哨兵与 slave 之间通讯正常,这时 3 个 slave 其中 1 个经过哨兵投票后,提升为新 master,如果恰好此时 server1 仍然连接的是旧的 master,而 server2 连接到了新的 master 上。
此时可能导致数据的不一致问题,如基于 setNX 指令的分布式锁,可能会拿到相同的锁;基于 incr 生成的全局唯一 id,也可能出现重复。
集群(cluster)模式下的脑裂:
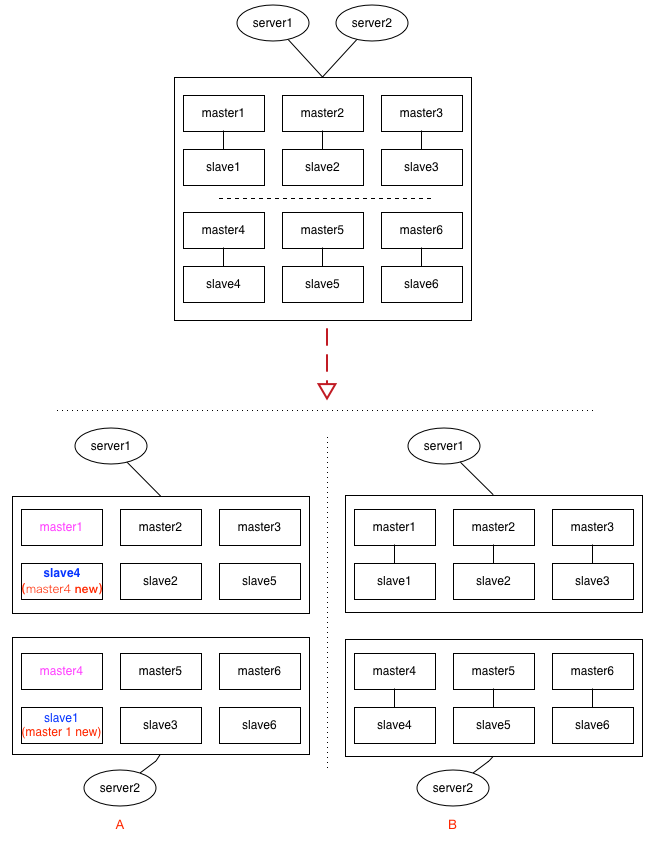
custer 模式下,这种情况要更复杂,见上面的示意图,集群中有 6 组分片,每给分片节点都有 1 主 1 从,如果出现网络分区时,各种节点之间的分区组合都有可能,上面列了 2 种情况:
情况A:
假设 master1 与 slave4 落到同 1 个分区,这时 slave4 经过选举后,可能会被提升为新的 master4,而另一个分区里的 slave1,可能会提升为新的 master1。cluster 中 key 的定位是依赖 slot(槽位),情况 A 经过这一翻折腾后,master1 与 master4 上的 slot,出现了重复,在二个分区里都有。类似的,如果依赖 incr 及 setNX 的应用场景,都会出现数据不一致的情况。
情况B:
如果每给分片内部的逻辑(即:主从关系)没有乱,只是恰好分成二半,这时 slot 整体上看并没有出现重复,如果原来请求的 key 落在其它区,最多只是访问不到,还不致于发生数据不一致的情况。(即:宁可出错,也不要出现数据混乱)
2. 脑裂原因
2.1 网络问题:导致 Redis Master 节点跟 Redis Slave 节点和 Sentinel 集群处于不同的网络分区,此时因为 Sentinel 集群无法感知到 master 的存在,所以将 Slave 节点提升为 Master节点。此时存在两个不同的 Master 节点,就像一个大脑分裂成了两个。
2.2 主机资源问题:Redis Master 节点所在的服务器上的其他程序临时占用了大量资源(例如 CPU 资源),导致主库资源使用受限,短时间内无法响应心跳,于是 Sentinel 集群重新选举了新的 Master,当其它程序不再使用资源时,旧 Master 节点又恢复正常,同一集群下出现两个 Master;
2.3 Redis 主节点阻塞:主库自身遇到了阻塞的情况,例如,处理 bigkey 或是发生内存 swap,短时间内无法响应心跳,还是会触发 Sentinel 机制,等主库阻塞解除后,又恢复正常的请求处理了。
3. 脑裂影响
当原主库并没有真的发生故障(例如主库进程挂掉),而是由于某些原因无法处理请求,也没有响应哨兵的心跳,才被哨兵错误地判断为客观下线的。结果,在被判断下线之后,原主库又重新开始处理请求了,而此时,哨兵还没有完成主从切换,客户端仍然可以和原主库通信;
如果客户端还在基于原来的主库继续写入数据,那么新的主库将无法同步这些数据,当网络问题解决之后,哨兵就会让原主库执行 slave of 命令,和新主库重新进行全量同步。而在全量同步执行的最后阶段,原主库需要清空本地的数据,加载新主库发送的 RDB 文件,这样一来,原主库在主从切换期间保存的新写数据就丢失了。
4. 脑裂预防
主从集群中的数据丢失事件,归根结底是因为发生了脑裂。所以,我们必须要找到应对脑裂问题的策略。
既然问题是出在原主库发生假故障后仍然能接收请求上,我们就开始在主从集群机制的配置项中查找是否有限制主库接收请求的设置。
通过查找,可以发现,Redis 已经提供了两个配置项来限制主库的请求处理,分别是 min-slaves-to-write 和 min-slaves-max-lag。
- min-slaves-to-write:这个配置项设置了主库能进行数据同步的最少从库数量,即至少要保证 N 个从库能进行数据同步;
- min-slaves-max-lag:这个配置项设置了主从库间进行数据复制时,从库给主库发送 ACK 消息的最大延迟(以秒为单位)。
有了这两个配置项后,我们就可以轻松地应对脑裂问题了。具体咋做呢?
我们可以把 min-slaves-to-write 和 min-slaves-max-lag 这两个配置项搭配起来使用,分别给它们设置一定的阈值,假设为 N 和 T。这两个配置项组合后的要求是,主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的请求了。
即使原主库是假故障,它在假故障期间也无法响应哨兵心跳,也不能和从库进行同步,自然也就无法和从库进行 ACK 确认了。这样一来,min-slaves-to-write 和 min-slaves-max-lag 的组合要求就无法得到满足,原主库就会被限制接收客户端请求,客户端也就不能在原主库中写入新数据了。
等到新主库上线时,就只有新主库能接收和处理客户端请求,此时,新写的数据会被直接写到新主库中。而原主库会被哨兵降为从库。
4.1 配置示例
假设我们将 min-slaves-to-write 设置为 1,把 min-slaves-max-lag 设置为 12s,把哨兵的 down-after-milliseconds 设置为 10s,主库因为某些原因卡住了 15s,导致哨兵判断主库客观下线,开始进行主从切换。同时,因为原主库卡住了 15s,没有一个从库能和原主库在 12s 内进行数据复制,原主库也无法接收客户端请求了。这样一来,主从切换完成后,也只有新主库能接收请求,不会发生脑裂,也就不会发生数据丢失的问题了。