1. 项目背景 ElasticJob 是一个分布式调度解决方案,旨在解决大型分布式软件系统中的定时任务管理问题,提供高效的任务调度和分布式资源管理。然而,现有的ElasticJob 解决方案在监控定时任务执行方面还有不足之处,为了确保系统资源的有效利用并降低定时任务执行过程中可能出现的问题,我们决定对 ElasticJob 进行定时任务执行监控改造。
1.1 改造目标 任务状态监控 :实时掌握任务状态,提供分布式任务执行的详细报告,包括进行中、失败、成功等状态,以便快速发现和解决问题;告警机制 :在任务发生故障或状态异常时,及时发送告警通知到相关人员,缩短故障处理周期,确保业务的稳定运行。1.2 改造方案 通过对 ElasticJob 定时任务执行监控的改造,我们希望实现对定时任务的更加智能化地管理,确保高效、稳定地进行各类后台任务处理,降低故障风险
数据采集整合 :扩展 ElasticJob 的监控功能,通过引入第三方监控组件如 Prometheus 或者自研组件来采集 ElasticJob 中的各项定时任务执行状态数据实施告警机制 :通过配置告警规则,当任务执行异常时可以自动触发告警通知,通知方式包括企业微信等。2. 方案明细 通过整合springboot,prometheus中guage的使用,记录当前触发定时任务执行时间,以及预计下次执行时间。在prometheus语法中,通过time()函数对比计算,查询延迟执行的job任务,实时推送告警。
1、监控开源组件 prometheus,并通过 prometheus alertmanager 进行企业微信告警
2、SimpleJob 依赖接口组件实现,对其 ElasticJob 接口二次封装,向 prometheus上报统计值数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public interface MonitoredJob extends SimpleJob Logger log = LoggerFactory.getLogger(MonitoredJob.class); @Override default void execute (ShardingContext shardingContext) try { Class<?> classTarget = this .getClass(); TaskJob taskJob = classTarget.getAnnotation(TaskJob.class); GaugeMetricService gaugeMetricService = SpringContextUtil.getBean(GaugeMetricService.class); Assert.notNull(gaugeMetricService, "MonitoredJob error, gaugeMetricService is null" ); gaugeMetricService.gaugeMonitor(taskJob.jobName(), shardingContext.getShardingParameter(), taskJob.cron()); } catch (Throwable var5) { log.error("doExecute failed" , var5); } doExecute(shardingContext); } void doExecute (ShardingContext shardingContext) }
GaugeMetricService 负责自定义指标数据采集和上报,具体实现如下所示。这里旨在通过 Gauge 上报 job 下次执行时间的时间戳值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 @Slf 4j@Service public class GaugeMetricService @Resource private CronTimeAfterService cronTimeAfterService; public void gaugeMonitor (String taskJobName, String shardingParameter, String cron) log.info("GaugeMetric taskJobName=" + taskJobName); if (StringUtils.isEmpty(taskJobName) || StringUtils.isEmpty(cron) || !CronExpression.isValidExpression(cron)) { return ; } try { Map<String, String> tags = new LinkedHashMap<>(); tags.put("sharding" , StringUtils.isEmpty(shardingParameter) ? "" : shardingParameter); tags.put("taskJob" , taskJobName); DnReturnGaugeMetric dnReturnGaugeMetric = new DnReturnGaugeMetric(cron); Iterable<Tag> tag = getTagList(tags, dnReturnGaugeMetric); log.info("tag=" + tag.toString() + ";value=" + dnReturnGaugeMetric.applyAsDouble(this .cronTimeAfterService)); Metrics.gauge("simple_job_monitor" , tag, this .cronTimeAfterService, dnReturnGaugeMetric); } catch (Exception var7) { log.warn("GaugeMetric gaugeMonitor failed:{}" , var7.getMessage()); } } private Iterable<Tag> getTagList (Map<String, String> tagsMap, DnReturnGaugeMetric dnReturnGaugeMetric) Iterable<Tag> tagsWithId = Collections.emptyList(); Map.Entry<String, String> entry; if (tagsMap != null && tagsMap.size() > 0 ) { for (Iterator<Map.Entry<String, String>> var4 = tagsMap.entrySet().iterator(); var4.hasNext(); tagsWithId = Tags.concat(tagsWithId, entry.getKey(), entry.getValue())) { entry = var4.next(); } } return tagsWithId; } }
DnReturnGaugeMetric,通过实现ToDoubleFunction方法,实时计算预计下次任务执行时间点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Data @NoArgsConstructor @AllArgsConstructor public class DnReturnGaugeMetric implements ToDoubleFunction <CronTimeAfterService > private String cron; @Override public double applyAsDouble (CronTimeAfterService value) return value.dnReturnTimeAfter(this .cron); } }
CronTimeAfterService 负责计算下次 job 的执行时间:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Slf 4j@Service public class CronTimeAfterService public double dnReturnTimeAfter (String cron) double timeAfter = 0.0 D; if (StringUtils.isEmpty(cron) || !CronExpression.isValidExpression(cron)) { return timeAfter; } try { CronExpression cronExpression = new CronExpression(cron); Date dateV = cronExpression.getTimeAfter(new Date()); timeAfter = (double ) (dateV.getTime() / 1000L ); } catch (Exception var7) { log.error("dnReturnTimeAfter exec failed" , var7); } return timeAfter; } }
3、原有实现 SimpleJob 的任务类,改成实现 MonitoredJob 接口即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Component @Slf 4j@TaskJob (jobName = "my-monitored-job" , cron = "/20 * * * * ? *" , description = "自定义 actuator job 监控" , shardingItemParameters = "0=0-1-2-3,1=4-5-6-7,2=8-9-10-11,3=12-13-14-15" , shardingTotalCount = 4 ) public class MyJob implements MonitoredJob @Override public void doExecute (ShardingContext shardingContext) log.info("分片数信息:" + shardingContext.getShardingItem()); log.info("分片参数:" + shardingContext.getShardingParameter()); } }
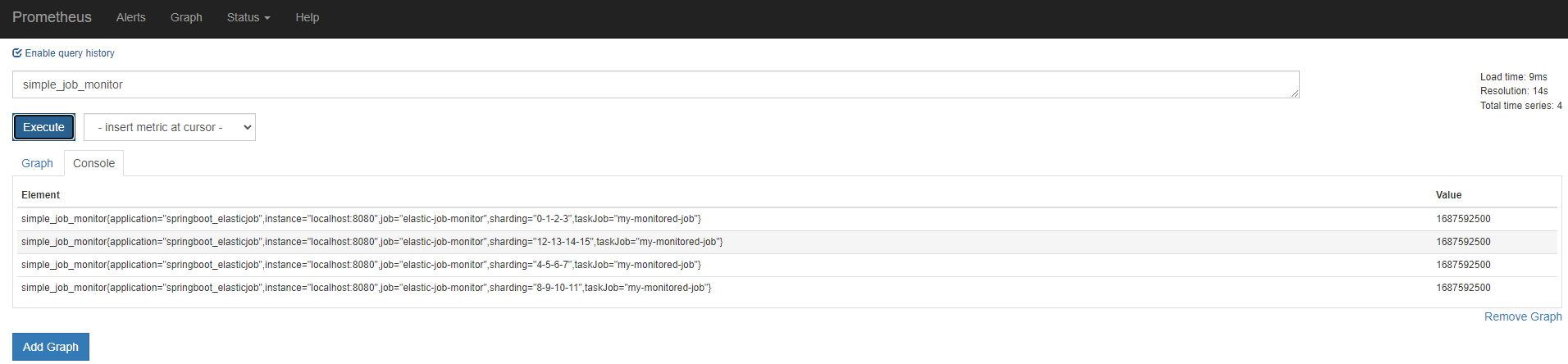
3. 告警规则 访问 prometheus 后台,自定义上报的 simple_job_monitor 指标如下所示:
我们可以在 alertmanager 配置如下告警规则:
1 (time() > bool (sum(simple_job_monitor) by (application, sharding, taskJob))+30)>0
其中 (time() > bool (sum(simple_job_monitor) by (application, sharding, taskJob))+30)表示当前时间是否大于下次 job 的执行时间 + 30s,是则返回1,否则返回 0。若最终返回 1 那么符合大于 0 的告警规则,则会推送企业微信告警。
关于告警的配置和实现推荐推荐阅读 基于-Prometheus-Actuator-Grafana-构建支付监控体系
4. 推荐阅读