1. Canal
1.1 简介
canal 主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
1.2 工作原理
1.2.1 MySQL主备复制原理
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
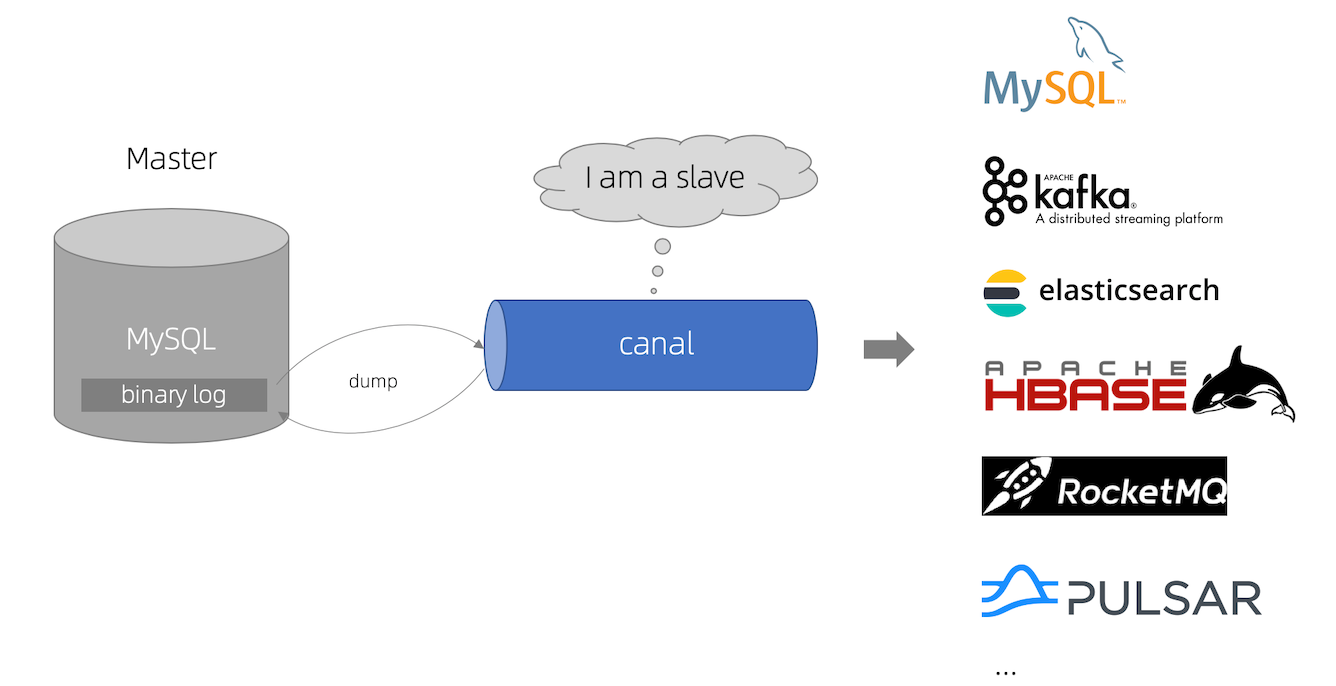
1.2.2 canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
2. 项目应用
在 Tom 项目实际应用中,在订单售后模块,使用 canal 主要是为了实现将 MySQL 数据库中数据的更新实时同步至 ElasticSearch,使用 canal 的 kafka 模式实现。
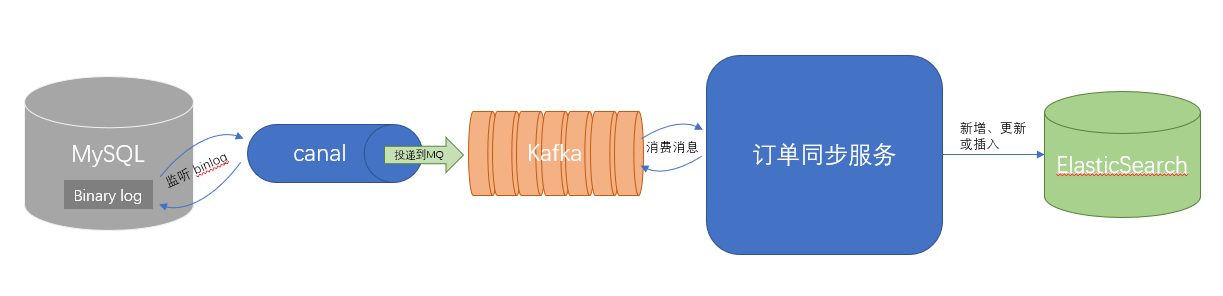
canal 会将 MySQL binlog 更新信息投递至 kafka 中,而订单同步服务则需要自行实现轮询监听 kafka 将信息进行解析然后同步更新至 ElasticSearch。其中订单同步服务实现 kafka 信息消费可以参考示例 MQ数据消费。
当同步服务解析消费到 kafka 的消息后,可以根据消息的 topic、操作的类型(insert,update, delete)和操作的表(如订单表、售后表等)来对数据进行筛选、拆分和转化,最后更新到 ES 中。
spring 集成了 elasticsearch,可以很方便的通过操作 ElasticsearchRepository 对象的基础 CRUD API 来操作。