1. Ingest Pipeline
相关阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/ingest-apis.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/ingest-processors.html
1.1 Ingest Node
Elasticsearch 5.0 后,引⼊的⼀种新的节点类型。默认配置下,每个节点都是 Ingest Node,其具有如下能力:
- 具有预处理数据的能⼒,可拦截 Index 或 Bulk API 的请求
- 对数据进⾏转换,并重新返回给 Index 或 Bulk API
利用 Ingest Node 则⽆需 Logstash,就可以进⾏数据的预处理,例如为某个字段设置默认值、重命名某个字段的字段名、对字段值进⾏ Split 操作;同时⽀持设置 Painless 脚本,对数据进⾏更加复杂的加⼯。
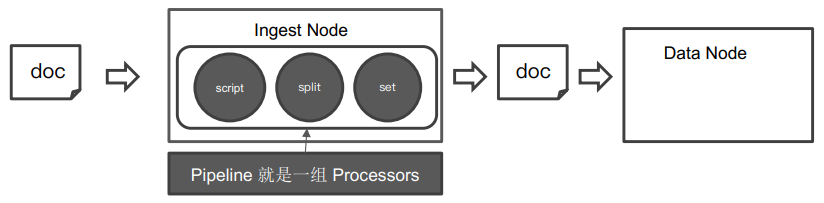
1.2 Pipeline & Processor
Pipeline 即管道会对通过的数据(⽂档),按照顺序进⾏加⼯,Processor 则是 Elasticsearch 对⼀些加⼯的⾏为进⾏了抽象包装。Elasticsearch 有很多内置的 Processors。也⽀持通过插件的⽅式,实现⾃⼰的 Processor,定义参考下图:
1.3 Pipeline API

1.4 示例
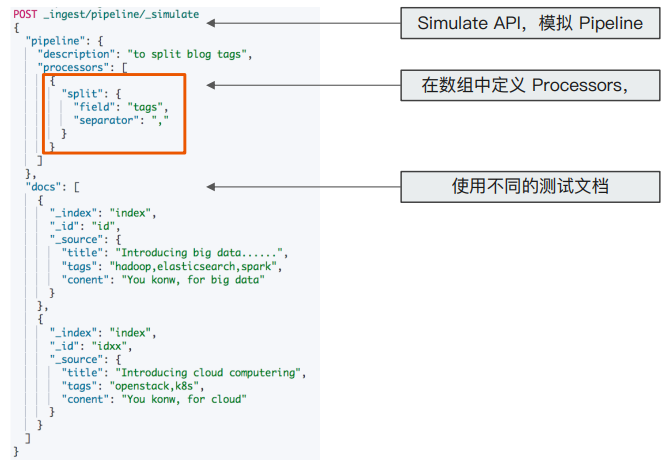
1.4.1 字符串切分
观察下图,processors 以一个数组进行定义,下面示例中即是对测试文档中的 tags 字段按照逗号进行切分:
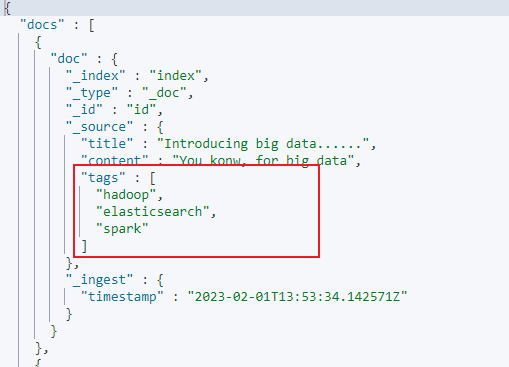
响应结果如下,tags 字段按照逗号分隔后以数组的形式进行响应:
1.4.2 增加字段
在 processors 中定义增加字段 views并设置默认值为0,在对 docs 文档进行测试分析时会响应 views 字段,参考下图:

1.4.3 使用 pipeline
我们可以按照自定义的 pipeline 来对数据按一定格式进行处理后写入的 ES 之中,下面我们新增一个名称为 blog_pipeline 的 pipeline,DSL 如下,processors 支持对 tags 字段进行逗号分隔且对文档增加字段 views:
1 | PUT _ingest/pipeline/blog_pipeline |
可以使用 blog_pipeline 来更新数据,例如按照指定 pipeline 的格式存入一篇 id 为2 的新文档,其中 id 为 2 的文档会以 blogs_pipeline 的格式存储和显示文档信息。
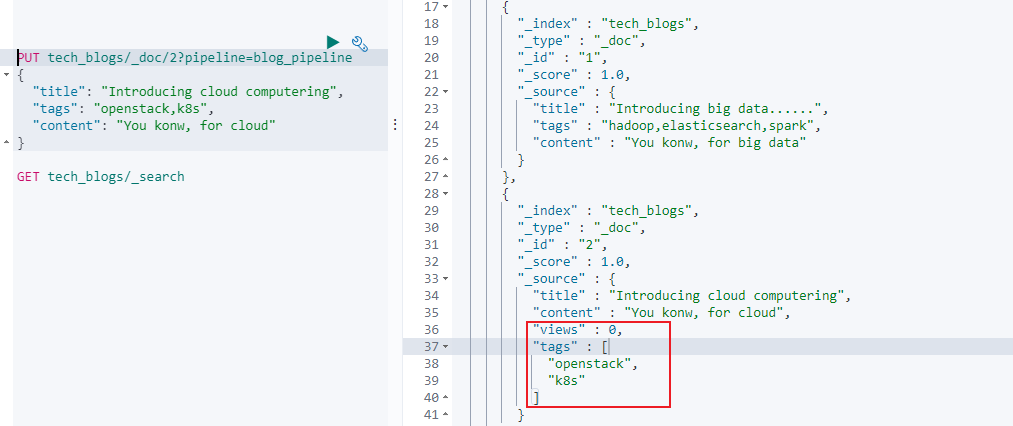
另外 id 为 1 的文档还是按照原有默认的格式进行存入的,并未使用 pipeline 的方式进行存入。如果需要 id 为 1 的文档以 id 为 2 的格式进行存储显示,我们需要使用 _update_by_query 进行文档更新。比如下面的 DSL 中即是对所有不包含 views 进行更新(根据 blogs_pipeline 的定义,blogs_pipeline 更新的文档存在 views 字段):
1 | POST tech_blogs/_update_by_query?pipeline=blog_pipeline |
2. Painless Script
相关阅读:https://www.elastic.co/guide/en/elasticsearch/painless/7.4/painless-guide.html
Painless Script 从 Elasticsearch 5.x 后引⼊,专⻔为 Elasticsearch 设计,扩展了 Java 的语法。6.0 开始,ES 只⽀持 Painless。Groovy, JavaScript 和 Python 都不再⽀持。Painless ⽀持所有 Java 的数据类型及 Java API ⼦集,且具备⾼性能 / 安全、⽀持显示类型或者动态定义类型的特性。
2.1 使用场景
- 可以对⽂档字段进⾏加⼯处理
- 更新或删除字段,处理数据聚合操作
- Script Field:对返回的字段提前进⾏计算
- Function Score:对⽂档的算分进⾏处理
- 在 Ingest Pipeline 中执⾏脚本
- 在 Reindex API,Update By Query 时,对数据进⾏处理
2.1.1 pipeline 使用 script
查看下述示例,在 pipeline 中使用 script 脚本来获取文档中 content 字段的长度:
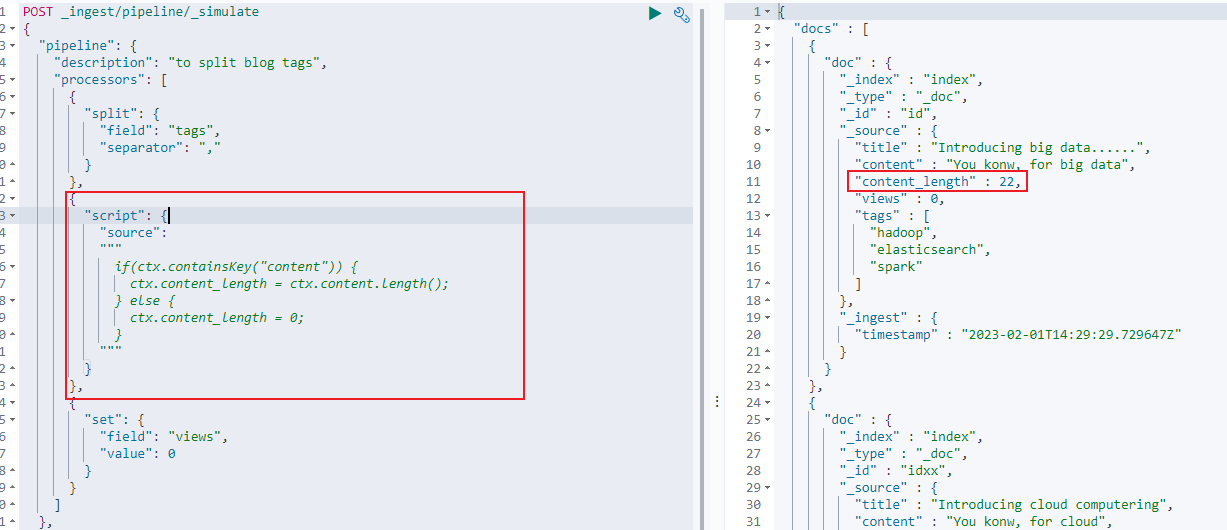
2.1.2 script 更新文档
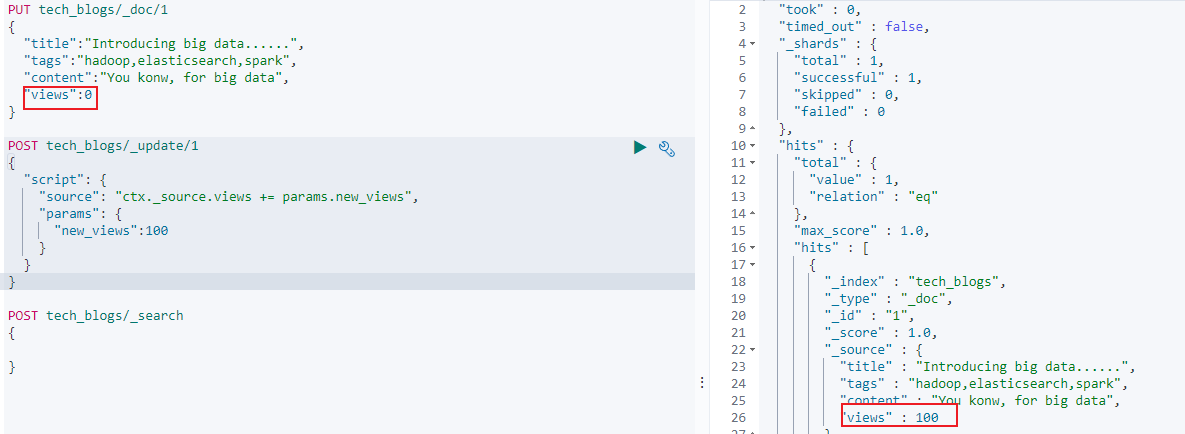
可以在更新文档时使用 painless script 来更新文档字段数据,例如下述即是对索引中的文档 views 字段累加上 100:
1 | POST tech_blogs/_update/1 |
views 从 0 变更为 100:
ES 也支持将脚本进行保存,再进行更新的时候可以通过对应脚本ID 来使用对应脚本。如下便是创建一个 ID 为 update_views 的脚本:
1 | POST _scripts/update_views |
可以通过如下方式进行使用指定脚本:
1 | POST tech_blogs/_update/1 |
2.1.3 查询时使用 script
例如在查询时返回一个新的字段 rnd_views,其值有 scripts 随机生成:
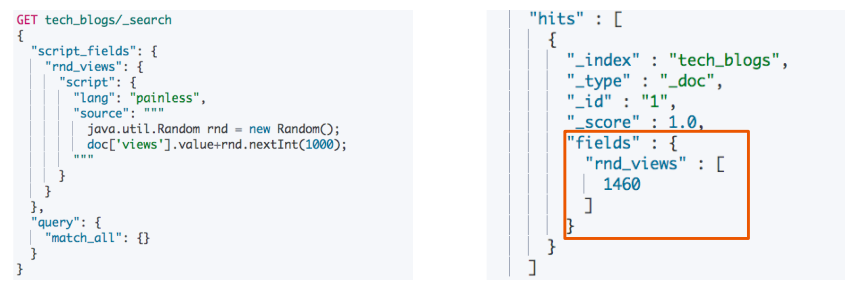
2.2 Painless 脚本访问字段
在不同场景的使用上下文中,painless 脚本访问字段的语法各不相同,参考如下:
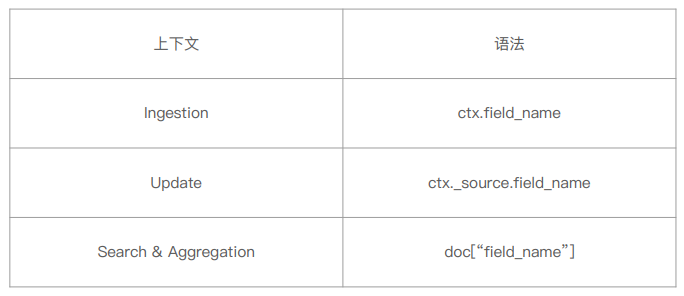
2.3 脚本缓存
Elasticsearch 执行脚本时需要对脚本进行编译,而编译的开销相较⼤。因此 Elasticsearch 会将脚本编译后缓存在 Cache 中,默认缓存 100 个脚本。我们可以自行更改相关脚本配置参数,参考如下: