相关阅读:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/query-dsl-nested-query.html
真实世界中有很多重要的关联关系,比如银⾏账户有多次交易记录或者目录⽂件有多个⽂件和⼦⽬录。
范式化设计 (Normalization) 的主要目标是“减少不必要的更新”,数据库越范式化,就需要 Join 越多的表,因此⼀个完全范式化设计的数据库会经常⾯临 “查询缓慢”的问题。范式化简化了更新,但是数据“读”取操作可能更多。
反范式化设计,不使⽤关联关系,⽽是在⽂档中保存冗余的数据拷⻉。由于⽆需处理 Join 操作,因此数据读取性能好。但是缺点是不适合在数据频繁修改的场景,比如⼀条数据(⽤户名)的改动,可能会引起很多数据的更新。
Elasticsearch 并不擅⻓处理关联关系。我们⼀般采⽤以下四种⽅法处理关联:
对象类型冗余(通过对象冗余,避免数据关联)
嵌套对象(Nested Object)
⽗⼦关联关系(Parent / Child )
1. 对象类型冗余
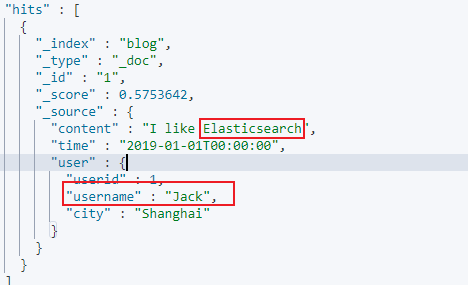
下面是一个 blog 文档,表示博客信息。除了博客信息之外,还通过 user 对象来冗余来存储博客作者信息。因此通过嵌套对象类型数据,来避免 join 关联。但是如果作者信息发⽣变化,需要修改相关的博客⽂档,因此不适合在数据频繁修改的场景。
1 | PUT blog/_doc/1 |
我们可以通过⼀条查询即可获取到博客和作者信息,查询如下:
1 | POST blog/_search |
响应如下:
但是当对象是一个数组类型时,通过简单的 bool query 是存在问题的。例如索引 my_movies 存在两个 actors 对象,以数组的格式进行存储:
1 | POST my_movies/_doc/1 |
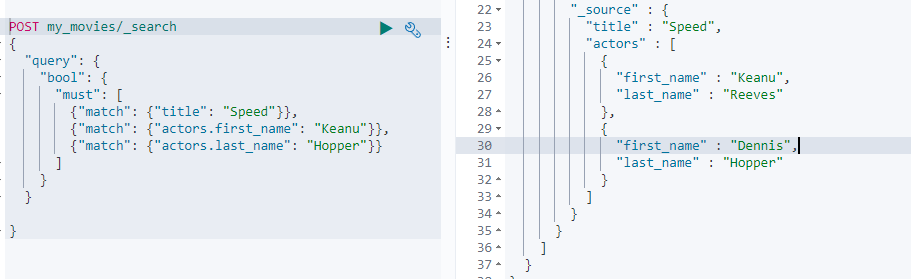
假设现在我们需要查询获取 first_name 为 Keanu 且 last_name 为 Hopper,按照预想查询结果应该是空,但是实际情况是能够查询到结果:
这是因为 ES 在存储数据时,内部对象的边界并没有考虑在内,JSON 格式被处理成扁平式键值对的结构,比如上述示例的 actors 数组实际是以如下格式存储的:
1 | "title":"Speed" |
因此当对多个字段进⾏查询时,才会导致意外的搜索结果,可以⽤ Nested Data Type 解决这个问题。
2. Nested Object
Nested 数据类型,允许对象数组中的对象被独⽴索引。使⽤ nested 和 properties 关键字,将上述示例中所有 actors 索引到多个分隔的⽂档。在内部, Nested ⽂档会被保存在两个 Lucene ⽂档中,在查询时做 join 处理。
还是以索引 my_movies 为例,需要修改 mapping 对 actors 增加 Nested Data Type:
1 | PUT my_movies |
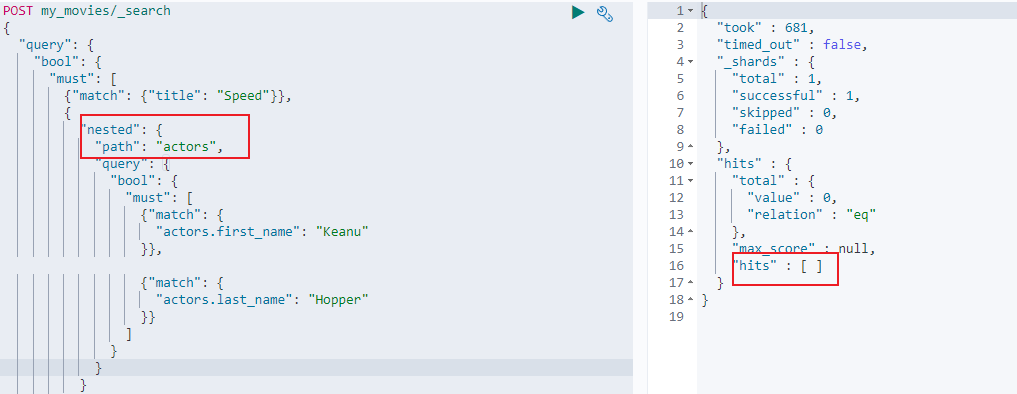
然后通过使用 Nested 查询来替代普通的 bool 查询以达到我们需要的效果,其中还需指定 path 值为 actors,即对应的对象数组名称:
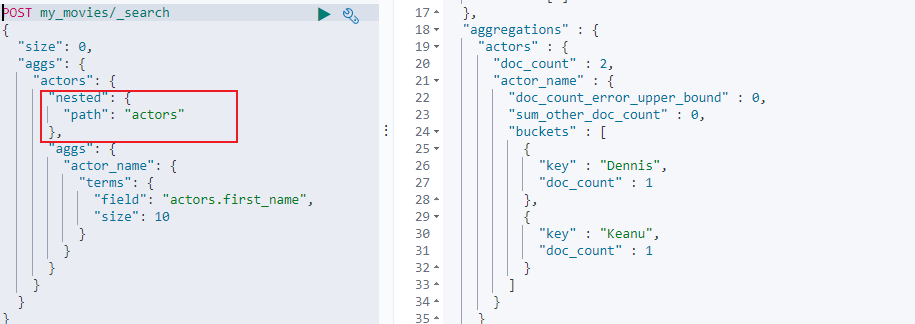
同时在嵌套对象是对象数组类型的情况下,普通的 Aggregation 无法生效。比如下面使用 actors.first_name 进行分桶聚合,聚合结果为空:

需要使用 Nested 进行聚合才能生效,具体如下所示: