1. 分布式系统的近似统计算法
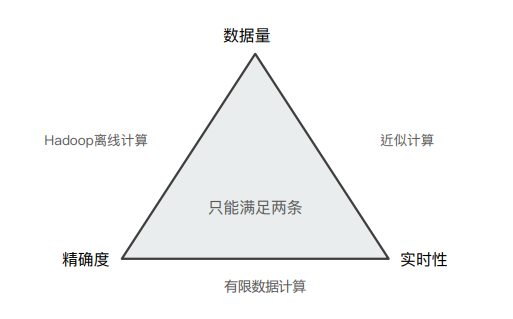
在分布式系统中,数据量、精确度和实时性三个指标只能同时满足其中两个。比如在数据量比较大的情况下,为了保证数据的实时性,那么就需要采用近似计算来提高实时性从而丢失了数据的精确度。
2. Terms 精度问题
ES 在进行聚合分析时同样也存在精度丢失的问题,下图是聚合分析的执⾏流程:
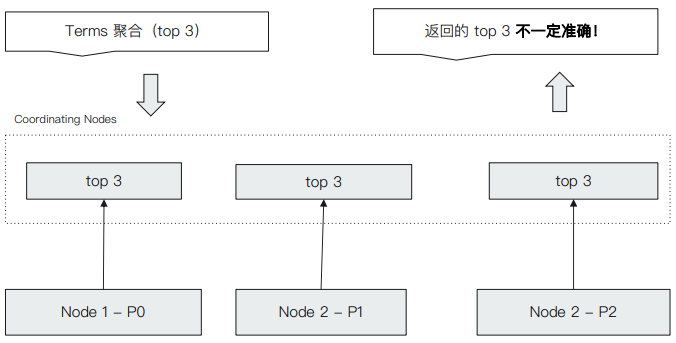
当 ES 数据量较大时,数据需要存放在不同节点的分片上,假设现在数据存放在 node1、node2 和 node3 三个节点分片上,那么要获取文档数最大的前三个数据时,其执行流程是先从三个节点分片上先分别获取最大的三个数据,然后在 coordinating nodes 上从 9 个数据再获取前三个最大的数据,并返回。但是这并不能保证结果正确。
比如下述示例中,ES 中共存放 12 条 A 记录,6 条 B 记录,5 条 C 记录和 6 条 D 记录,其按下图规则存放在不同的节点上。为了获取前三个文档数最大的记录,第一个节点会返回 A(6) / B(4) / C(4),第二个节点则返回 A(6) / B(2) / D(3),那么再次基础上最终结果将会返回 A(12) / B(6) / C(4)。但显然,正确的结果应该是 A(12) / B(6) / D(3)。
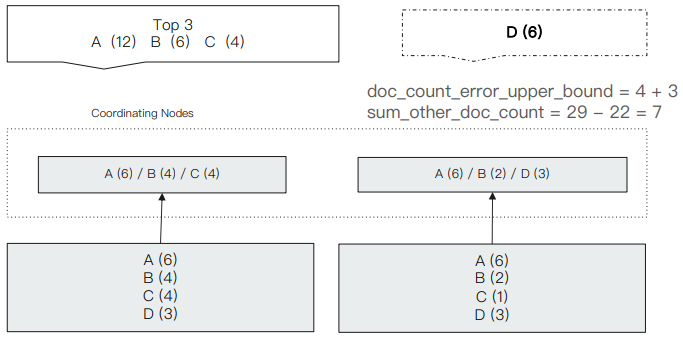
在 Terms Aggregation 的返回中有两个特殊的数值:
- doc_count_error_upper_bound : 被遗漏的 term 分桶,包含的⽂档,有可能的最⼤值
- sum_other_doc_count: 除了返回结果 bucket 的 terms 以外,其他 terms 的⽂档总数(总数-返回的总数)
3. Terms 精度问题处理
Terms 聚合分析不准的原因,数据分散在多个分⽚上, Coordinating Node ⽆法获取数据全貌。有两种处理方案:
- 当数据量不⼤时,设置 Primary Shard 为 1,实现准确性
- 在分布式数据上,设置 shard_size 参数,提⾼精确度,原理即是每次从 Shard 上额外多获取数据,提升准确率。
比如我们现在新建一个索引 my_flights,并将其分片设定为 20:

然后将 kibana 自带的索引 kibana_sample_data_flights 的数据导入到 my_flights 中:
1 | POST _reindex |
下述 DSL 检索语句对字段 OriginWeather 进行分桶,并指定 shard_size 的值为 1,且打开开关 show_term_doc_count_error,以此我们便能观察到每个分桶中被遗漏的 term 分桶数量:
1 | GET my_flights/_search |
响应如下:
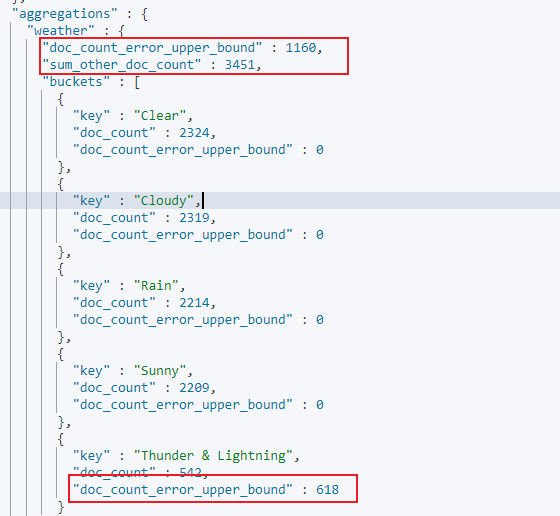
通过增加 shard_size 的值,我们便可以提高 terms 的数据准确度,例如当 shard_size 的值为 10 时,此时 doc_count_error_upper_bound 的值为 0,此时就表示数据是准确的。
调整 shard size ⼤⼩,可以降低 doc_count_error_upper_bound 来提升准确度,会增加整体计算量,提⾼了准确度,但会降低相应时间。
Shard Size 默认⼤⼩设定符合 shard size = size *1.5 +10。