相关阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/search-aggregations-metrics.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/search-aggregations-bucket.html
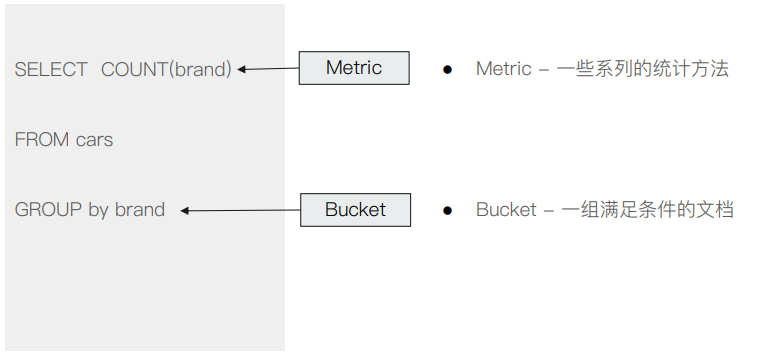
观察下图,所谓 metrix 即是一系列的统计方法,而 bucket 则是一组满足条件的文档。
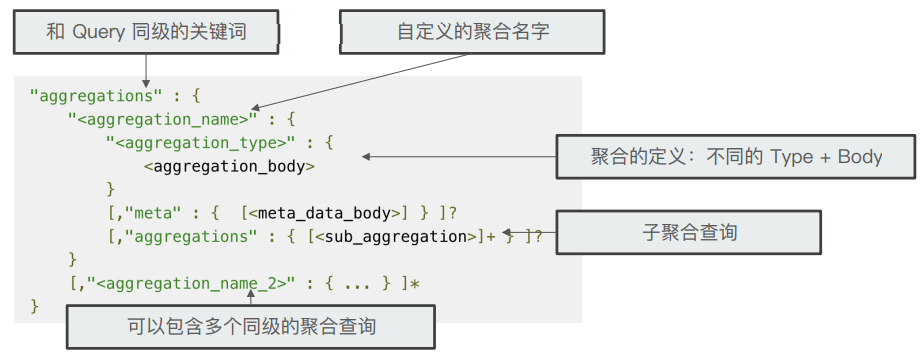
1. Aggregation 语法
Aggregation 属于 Search 的一部分。一般情况下,建议将其 Size 指定为 0。为 0 时只会返回聚合结果,而不会返回查询结果。
例如,我们需要查询员工的最低、最高工资以及平均工资,可以通过如下示例进行检索:
1 | POST employees/_search |
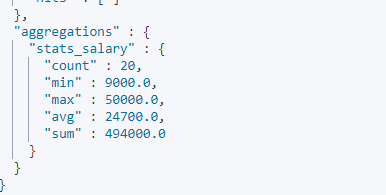
当然,也可以简单的使用 stats 聚合类型查询平均值、累计值等信息:
1 | POST employees/_search |
响应信息如下:
2. Metrix Aggregation
- 单值分析:只输出⼀个分析结果
- min, max, avg, sum
- cardinality (类似 distinct count)
- 多值分析:输出多个分析结果
- stats, extended_stats
- percentiles, percentile_ranks
- top_hits (排在前⾯的示例)
以 top_hits 为例,可以通过如下 DSL 获取年龄较大的前三位员工的信息,size 用于控制聚合响应条数:
1 | POST employees/_search |
3. Bucket Aggregation
Bucke 即是按照⼀定的规则,将⽂档分配到不同的桶中,从⽽达到分类的⽬的。ES 提供的⼀些常⻅的 Bucket Aggregation:
- Terms
- 数字类型
- Range / Data Range
- Histogram / Date Histogram
另外 Bucket Aggregation ⽀持嵌套,也就在桶⾥再做分桶。
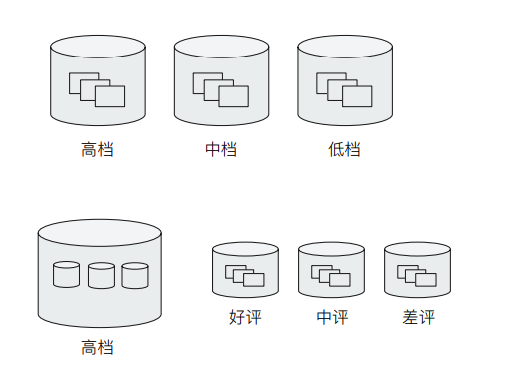
3.1 Terms Aggregation
text 类型字段需要打开 fielddata,才能进⾏ Terms Aggregation,其满足如下规则:
- keyword 默认⽀持 doc_values
- text 需要在 mapping 中修改对应类型字段的 fielddata 的值为 true。text 类型的 terms aggregation 会按照分词后的结果进⾏分桶。
下面演示对 keyword 类型子字段进行 terms aggregation,示例如下:
1 | POST employees/_search |
响应信息如下:
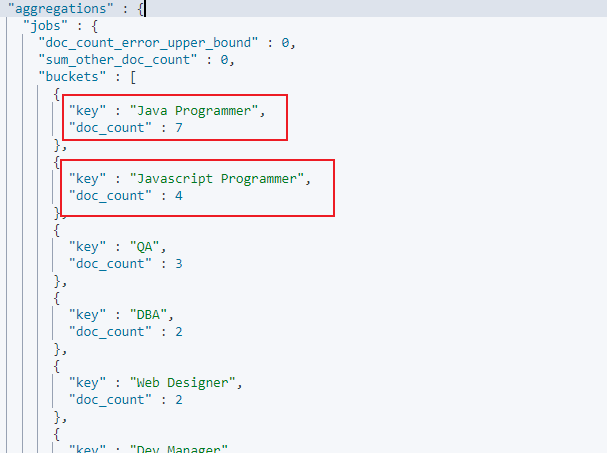
如果直接给 text 字段 job 进行 terms aggregation 聚合,则会报错。此时需要修改 mapping 的 fielddata:
1 | POST employees/_search |
聚合响应结果如下,可以发现对于 text 类型的聚合分桶会先进行分词,例如将 Java Programmer 进行分词:

另外也可以再进行分桶时指定 size 来控制响应的条数 :
1 | POST employees/_search |
3.1.1 Terms 性能优化
相关阅读:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/tune-for-search-speed.html
使用 Terms Aggregation 对 keyword 类型进行聚合时,可以打开 eager_global_ordinals 开关以达到提高聚合效率的效果:
1 | PUT index |
3.2 数字类型聚合
3.2.1 Range Aggregation
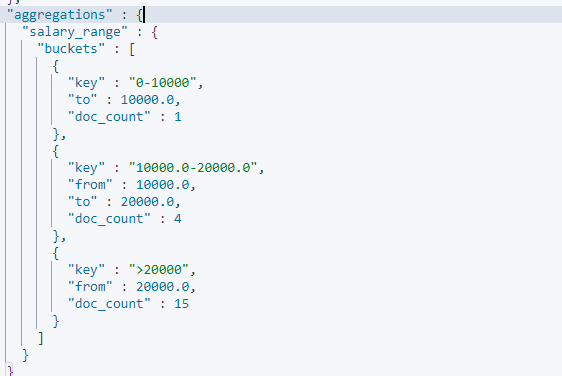
Bucket 支持按照数字的范围,进⾏分桶。在 Range Aggregation 中,可以⾃定义 Key。查看下面示例,可以按照员工薪水按照范围进行分桶聚合:
1 | POST employees/_search |
响应信息如下:
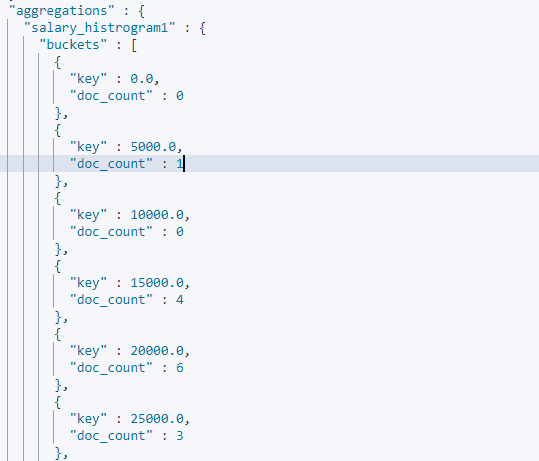
3.2.2 Histogram Aggregation
Histogram Aggregation 可以按照指定区间进行分桶聚合,查看下面示例,对员工工资按照区间 5000 进行分桶,并指定最小和最大的边界值:
1 | POST employees/_search |
响应信息如下:
4. 子聚合
Bucket 聚合分析允许通过添加⼦聚合分析来进⼀步分析,⼦聚合分析可以是 Bucket 或者 Metric。
比如按照工作类型分桶,并统计工资信息:
1 | POST employees/_search |
响应信息如下:

又或者先按照⼯作类型分桶,然后按性别分桶,并统计⼯资信息,示例如下:
1 | POST employees/_search |
响应信息如下:
