1. 排序
Elasticsearch 默认采⽤相关性算分对结果进⾏降序排序,可以通过设定 sorting 参数,⾃⾏设定排序,如果不指定 _score,算分为 Null。⽀持多个字段排序。例如下面示例中按照时间字段进行逆序排序:
1 | POST /kibana_sample_data_ecommerce/_search |
响应如下:
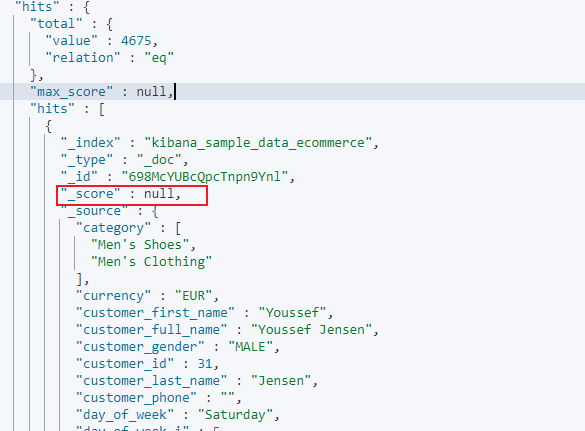
也可以按照多字段进行排序,示例如下:
1 | POST /kibana_sample_data_ecommerce/_search |
2. 排序实现
排序是针对字段原始内容进⾏的。 倒排索引⽆法发挥作⽤,因此需要⽤到正排索引。通过⽂档 Id 和字段快速得到字段原始内容。
Elasticsearch 有两种实现⽅法:
- Field Data
- Doc Values (列式存储,对 Text 类型⽆效)
Field data 与 Doc values 比较如下:
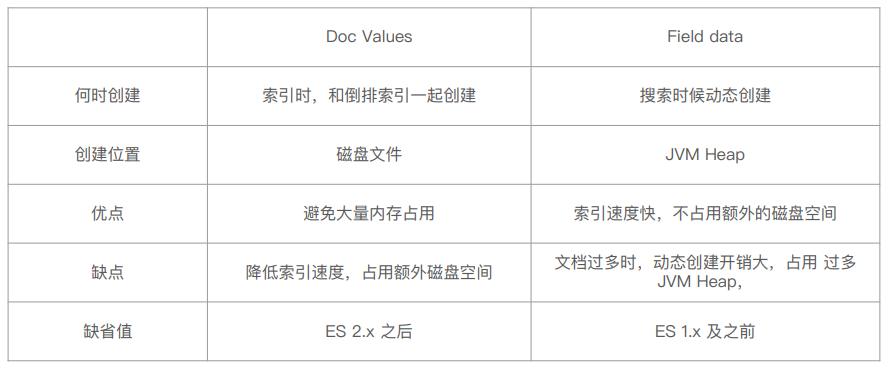
因为 Doc Values 仅支持 ES 2.x 之后的版本,且对 Text 类型无效。因此在 ES 7 对 Text 类型排序时会报错,示例如下:
1 | POST /kibana_sample_data_ecommerce/_search |
报错响应如下:
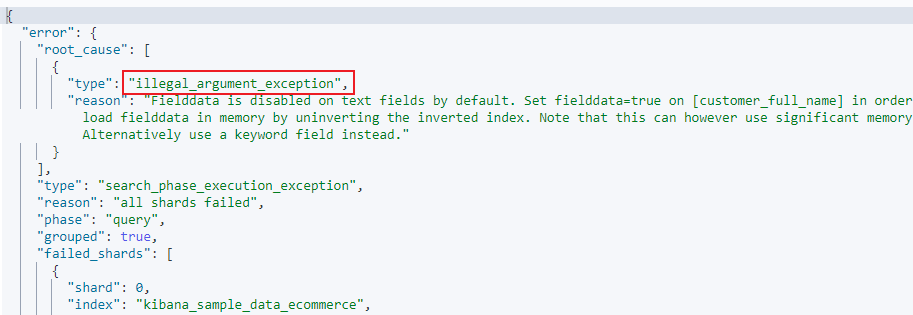
Field Data 默认关闭,可以通过 Mapping 设置打开。修改设置后,即时⽣效,⽆需重建索引。其他字段类型不⽀持,只⽀持对 Text 进⾏设定。打开后,可以对 Text 字段进⾏排序。但是对分词后的 term 排序,所以,结果往往⽆法满⾜预期,不建议使⽤。部分情况下打开,满⾜⼀些聚合分析的特定需求。
1 | PUT kibana_sample_data_ecommerce/_mapping |
Doc Values 默认启⽤,也可以通过 Mapping 设置关闭,优点是增加索引的速度 / 减少磁盘空间。如果重新打开,需要重建索引。因此需要明确不需要做排序及聚合分析才进行关闭。
1 | PUT test_keyword |