相关阅读:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/query-dsl-function-score-query.html
Elasticsearch 默认会以⽂档的相关度算分进⾏排序, 可以通过指定⼀个或者多个字段进⾏排序。使⽤相关度算分(score)排序,不能满⾜某些特定条件,且无法针对相关度,对排序实现更多的控制。
使用 Function Score Query 可以在查询结束后,对每⼀个匹配的⽂档进⾏⼀系列的重新算分,根据新⽣成的分数进⾏排序。其提供了⼏种默认的计算分值的函数:
- Weight :为每⼀个⽂档设置⼀个简单⽽不被规范化的权重
- Field Value Factor:使⽤该数值来修改 _score,例如将 “热度”和“点赞数”作为算分的参考因素
- Random Score:为每⼀个⽤户使⽤⼀个不同的随机算分结果
- 衰减函数: 以某个字段的值为标准,距离某个值越近,得分越⾼
- Script Score:⾃定义脚本完全控制所需逻辑
1. 按受欢迎度提升权重
希望能够将点赞多的 blog,放在搜索列表相对靠前的位置。同时搜索的评分,还是要作为排序的主要依据。其算分规则满足新的算分 = ⽼的算分 * 投票数。下面举个示例,添加如下三个文档,title 和 content 值都一样,只有点赞数 votes 值不一致
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| PUT /blogs/_doc/1
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 0
}
PUT /blogs/_doc/2
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 100
}
PUT /blogs/_doc/3
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 1000000
}
|
下面通过 function_score 进行查询,我们需要额外使用 field_value_factor 指明参与算分的指端,这里使用点赞数 votes:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes"
}
}
}
}
|
上述 DSL 查询结果 votes 为 1000000 的得分最高,votes 值为 0 的得分最低。查询响应结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| {
"_index" : "blogs",
"_type" : "_doc",
"_id" : "3",
"_score" : 133531.39,
"_source" : {
"title" : "About popularity",
"content" : "In this post we will talk about...",
"votes" : 1000000
}
},
{
"_index" : "blogs",
"_type" : "_doc",
"_id" : "2",
"_score" : 13.353139,
"_source" : {
"title" : "About popularity",
"content" : "In this post we will talk about...",
"votes" : 100
}
},
{
"_index" : "blogs",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"title" : "About popularity",
"content" : "In this post we will talk about...",
"votes" : 0
}
}
|
2. 使⽤ Modifier 平滑曲线
可以在 function_score 查询中增加 modifier 参数使得分数曲线更加平滑,其算法规则满足新的算分 = ⽼的算分 * log( 1 + 投票数 ),示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p"
}
}
}
}
|
查询出来的三个文档依然是 votes 为 1000000 的得分最高,votes 值为 0 的得分最低,但是其算分更加接近:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| {
"_index" : "blogs",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.8011884,
"_source" : {
"title" : "About popularity",
"content" : "In this post we will talk about...",
"votes" : 1000000
}
},
{
"_index" : "blogs",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.26763982,
"_source" : {
"title" : "About popularity",
"content" : "In this post we will talk about...",
"votes" : 100
}
},
{
"_index" : "blogs",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"title" : "About popularity",
"content" : "In this post we will talk about...",
"votes" : 0
}
}
|
除了 log1p,modifier 的值支持如下定义:

3. 引入 Factor
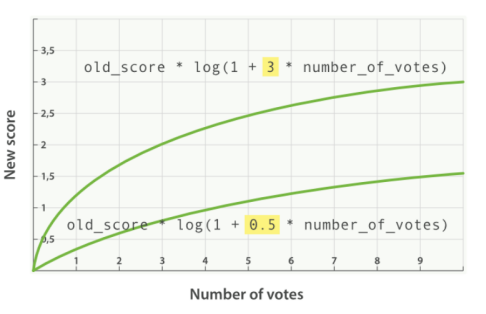
类似 modifier,我们可以指定可选因子 factor(默认值为 1),其算分规则满足新的算分 = ⽼的算分 * log( 1 + factor *投票数 ),factor 值越大,算分曲线越高,反之相反:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p" ,
"factor": 0.1
}
}
}
}
|
4. Boost Mode 和 Max Boost
可以使用 boost_mode 来对新计算的分数与查询的分数按指定模式相结合,并通过 max_boost 将算分控制在⼀个最⼤值。参数 boost_mode 有定义如下:
- multiply:算分与函数值的乘积
- sum:算分与函数的和
- min / max:算分与函数取 最⼩/最⼤值
- replace:使⽤函数值取代算分
查询示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p" ,
"factor": 0.1
},
"boost_mode": "sum",
"max_boost": 3
}
}
}
|
5. 一致性随机函数
一致性随机函数 random_score 生成从 0 到但不包括 1 的均匀分布的分数。为了保持每次对索引的查询的算分不变,需要指定 seed 和 filed,然后将根据此种子、所考虑文档的字段的最小值以及根据索引名称和分片 ID 计算的盐计算最终分数,以便具有相同值但存储在不同索引中的文档得到不同的分数。请注意,位于同一分片内且具有相同字段值的文档将获得相同的分数。查询示例如下:
1
2
3
4
5
6
7
8
9
10
11
| POST /blogs/_search
{
"query": {
"function_score": {
"random_score": {
"seed": 911119,
"field": "votes"
}
}
}
}
|