下面我们围绕着这个问题出发:如何从一个单词表中随机选出三个单词,这个表的建表语句如下:
1 | CREATE TABLE `words` ( |
1 | delimiter ;; |
1. 内存临时表
如果要要随机选择 3 个单词,首先,你会想到用 order by rand() 来实现这个逻辑。
1 | select word from words order by rand() limit 3; |
这个语句的意思很直白,随机排序取前 3 个。虽然这个 SQL 语句写法很简单,但执行流程却有点复杂的。我们先用 explain 命令来看看这个语句的执行情况。

Extra 字段显示 Using temporary,表示的是需要使用临时表;Using filesort,表示的是需要执行排序操作。 因此这个 Extra 的意思就是,需要临时表,并且需要在临时表上排序。这条语句的执行流程是这样的:
- 创建一个临时表。这个临时表使用的是 memory 引擎,表里有两个字段,第一个字段是 double 类型,为了后面描述方便,记为字段 R,第二个字段是 varchar(64) 类型,记为字段 W。并且,这个表没有建索引。
- 从 words 表中,按主键顺序取出所有的 word 值。对于每一个 word 值,调用 rand() 函数生成一个大于 0 小于 1 的随机小数,并把这个随机小数和 word 分别存入临时表的 R 和 W 字段中,到此,扫描行数是 10000。
- 现在临时表有 10000 行数据了。
- 初始化 sort_buffer。sort_buffer 中有两个字段,一个是 double 类型,另一个是整型。
- 从内存临时表中一行一行地取出 R 值和位置信息,分别存入 sort_buffer 中的两个字段里。这个过程要对内存临时表做全表扫描,此时扫描行数增加 10000,变成了 20000。
- 在 sort_buffer 中根据 R 的值进行排序。注意,这个过程没有涉及到表操作,所以不会增加扫描行数。
- 排序完成后,取出前三个结果的位置信息,依次到内存临时表中取出 word 值,返回给客户端。这个过程中,访问了表的三行数据,总扫描行数变成了 20003。
现在,我来把完整的排序执行流程图画出来。
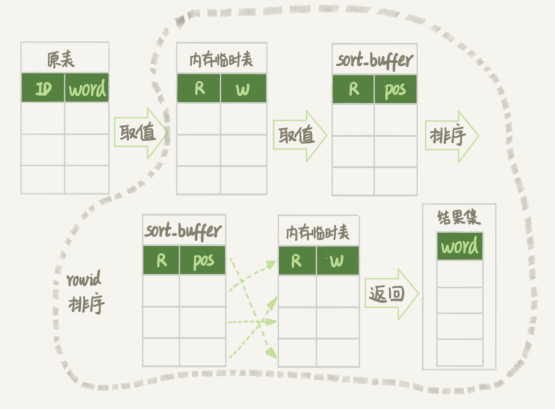
到这里,我来稍微小结一下:order by rand() 使用了内存临时表,内存临时表排序的时候使用了 rowid 排序方法。由于临时表使用的是 MEMORY 引擎不是索引组织表,获取临时表的数据不需要产生随机 io,因此优先使用 rowid 排序方式。
2. 磁盘临时表
那么,是不是所有的临时表都是内存表呢?其实不是的。tmp_table_size 这个配置限制了内存临时表的大小,默认值是 16M。如果临时表大小超过了 tmp_table_size,那么内存临时表就会转成磁盘临时表。
磁盘临时表使用的引擎默认是 InnoDB,是由参数 internal_tmp_disk_storage_engine 控制的。当使用磁盘临时表的时候,对应的就是一个没有显式索引的 InnoDB 表的排序过程。上面取随机三个单词的 SQL 语句的排序没有用到临时文件,而是采用是 MySQL 5.6 版本引入的一个新的排序算法,即:优先队列排序算法。接下来,我们就看看为什么没有使用临时文件的算法,也就是归并排序算法,而是采用了优先队列排序算法。
其实,我们现在的 SQL 语句,只需要取 R 值最小的 3 个 rowid。但是,如果使用归并排序算法的话,虽然最终也能得到前 3 个值,但是这个算法结束后,已经将 10000 行数据都排好序了。也就是说,后面的 9997 行也是有序的了。但,我们的查询并不需要这些数据是有序的。所以,想一下就明白了,这浪费了非常多的计算量。而优先队列算法,就可以精确地只得到三个最小值,如果不了解可以优先了解下优先队列算法。
3. 随机排序方法
再回到我们文章开头的问题,怎么正确地随机排序呢?你可以用下面这个流程:
取得整个表的行数,并记为 C。
取得 Y = floor(C * rand())。 floor 函数在这里的作用,就是取整数部分。
再用 limit Y,1 取得一行。
现在,我们再看看,如果我们按照随机算法 2 的思路,要随机取 3 个 word 值呢?你可以这么做:
- 取得整个表的行数,记为 C;
- 根据相同的随机方法得到 Y1、Y2、Y3;
- 再执行三个 limit Y, 1 语句得到三行数据。
下面这段代码,就是上面流程的执行语句的序列。
1 | select count(*) into @C from t; |
例如拼接成如下sql 执行,其中 20,40 和 32 为代码计算出来的随机行数入参:
1 | SELECT word FROM |