今天的文章里,我将会以 InnoDB 为例,剖析 MySQL 在事务支持方面的特定实现,并基于原理给出相应的实践建议,希望这些案例能加深你对 MySQL 事务原理的理解。
1. 隔离性与隔离级别
SQL 标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )
- 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
其中“读提交”和“可重复读”比较难理解,所以我用一个例子说明这几种隔离级别。假设数据表 T 中只有一列,其中一行的值为 1,下面是按照时间顺序执行两个事务的行为。
1 | create table T(c int) engine=InnoDB; |

我们来看看在不同的隔离级别下,事务 A 会有哪些不同的返回结果,也就是图里面 V1、 V2、V3 的返回值分别是什么。
- 若隔离级别是“读未提交”, 则 V1 的值就是 2。这时候事务 B 虽然还没有提交,但是 结果已经被 A 看到了。因此,V2、V3 也都是 2。
- 若隔离级别是“读提交”,则 V1 是 1,V2 的值是 2。事务 B 的更新在提交后才能被 A 看到。所以, V3 的值也是 2。
- 若隔离级别是“可重复读”,则 V1、V2 是 1,V3 是 2。之所以 V2 还是 1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
- 若隔离级别是“串行化”,则在事务 B 执行“将 1 改成 2”的时候,会被锁住。直到事务 A 提交后,事务 B 才可以继续执行。所以从 A 的角度看, V1、V2 值是 1,V3 的值 是 2。
2. 事务隔离的实现
在 MySQL 中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。
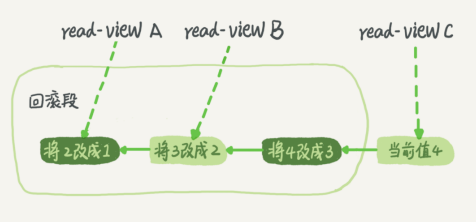
当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于 read-view A,要 得到 1,就必须将当前值依次执行图中所有的回滚操作得到。
基于上面的说明,我们来讨论一下为什么建议你尽量不要使用长事务。
长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间 ;除了对回滚段的影响,长事务还占用锁资源,也可能拖垮整个库。
3. 事务的启动方式
MySQL 的事务启动方式有以下几种:
- 显式启动事务语句, begin 或 start transaction。配套的提交语句是 commit,回滚语句是 rollback。
- set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个 select 语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行commit 或 rollback 语句,或者断开连接。
4. “快照”在 MVCC 里的工作机制
一个事务要更新一行,如果刚好有另外一个事务拥有这一行的行锁,它又不能这么超然了,会被锁住,进入等待状态。问题是,既然进入了等待状态,那么等到这个事务自己获取到行锁要更新数据的时候,它读到的值又是什么呢?
我给你举一个例子吧。下面是一个只有两行的表的初始化语句。
1 | CREATE TABLE `t` ( |
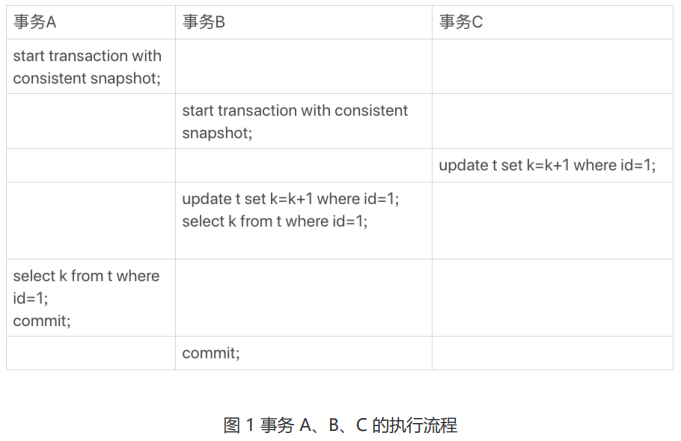
需要说明的是 begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个操作 InnoDB 表的语句,事务才真正启动。如果你想要马上启动一个事务,可以使用 start transaction with consistent snapshot 这个命令。在这个例子中,事务 C 没有显式地使用 begin/commit,表示这个 update 语句本身就是 一个事务,语句完成的时候会自动提交。
这时,如果我告诉你事务 B 查到的 k 的值是 3,而事务 A 查到的 k 的值是 1,你是不是感觉有点晕呢?所以,今天这篇文章,我其实就是想和你说明白这个问题,希望借由把这个疑惑解开的过程,能够帮助你对 InnoDB 的事务和锁有更进一步的理解。
在 MySQL 里,有两个“视图”的概念:
- 一个是 view。它是一个用查询语句定义的虚拟表,在调用的时候执行查询语句并生成结 果。创建视图的语法是 create view … ,而它的查询方法与表一样。
- 另一个是 InnoDB 在实现 MVCC 时用到的一致性读视图,即 consistent read view,用于支持 RC(Read Committed,读提交)和 RR(Repeatable Read,可重复读)隔离级别的实现。它没有物理结构,作用是事务执行期间用来定义“我能看到什么数据”。
InnoDB 里面每个事务有一个唯一的事务 ID,叫作 transaction id。它是在事务开始的时候向 InnoDB 的事务系统申请的,是按申请顺序严格递增的。
而每行数据也都是有多个版本的。每次事务更新数据的时候,都会生成一个新的数据版本,并且把 transaction id 赋值给这个数据版本的事务 ID,记为 row trx_id。同时,旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它。也就是说,数据表中的一行记录,其实可能有多个版本 (row),每个版本有自己的 row trx_id。
如图 2 所示,就是一个记录被多个事务连续更新后的状态。
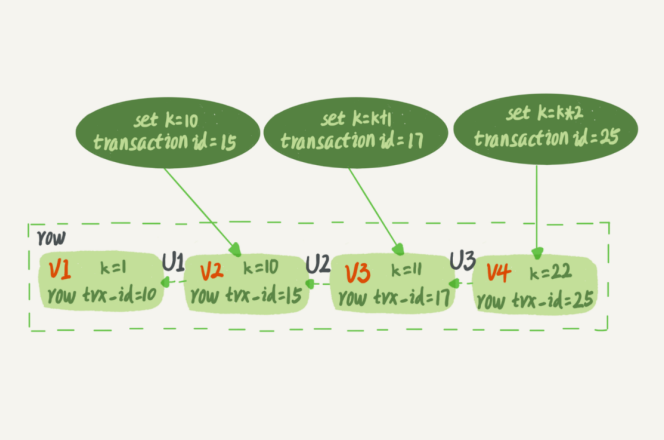
需要说明的是 V1、V2、V3 并不是物理上真实存在的,而是每次需要的时候根据当前版本和 undo log 计算出来的。比如,需要 V2 的时候,就是通过 V4 依次执行 U3、U2 算出来。在可重复读隔离级别下,事务在启动的时候就“拍了个快照”。注意,这个快照是基于整库的。InnoDB 利用了“所有数据都有多个版本”的这个特性,实现了“秒级创建快照”的能力。
接下来,我们继续看一下图 1 中的三个事务,分析下事务 A 的语句返回的结果,为什么是 k=1。假设事务 A 未开启事务之前的 row trx_id 为 10,版本号为 v1,开启事务后 row trx_id 值为 11,版本号为 v2。另外事务 C 的 row trx_id 为 13,版本号为 v4,那么事务 A 的上一版本为 v1。由于事务 A 开启事务后其他事务的更新对其不可见,因此 select k from t where id = 1 的值还是 v1 版本的值 1,所以我们称之为一致性读。
但是事务 B 的 update 语句按照一致性读好像不符合预期。如果事务 B 在更新之前查询一次数据,这个查询返回的 k 的值确实是 1。但是,当它要去更新数据的时候,就不能再在历史版本上更新了,否则事务 C 的更新就丢失了。因此,事务 B 此时的 set k=k+1 是在事务 C 的更新基础上的。所以,这里就用到了这样一条规则:更新数据都是先读后写的,而这个读,只能读当前的值,称为“当前读”(current read)。
再往前一步,假设事务 C 不是马上提交的,而是变成了下面的事务 C’,会怎么样呢?

事务 C’的不同是,更新后并没有马上提交,在它提交前,事务 B 的更新语句先发起了。 前面说过了,虽然事务 C’还没提交,但是 (1,2) 这个版本也已经生成了,并且是当前的最新版本。那么,事务 B 的更新语句会怎么处理呢?
这时候,事务 C’没提交,也就是说当前 id 为 1 的行锁还没释放。而事务 B 是当前读,必须要读最新版本,而且必须加锁,因此就被锁住了,必须等到事务 C’释放这个锁,才能继续它的当前读。