缓存回源的逻辑都是当缓存中查不到需要的数据时,回源到数据库查询。 这里容易出现的一个漏洞是,缓存中没有数据不一定代表数据没有缓存,还有一种可能是原始数据压根就不存在。
比如下面的例子。数据库中只保存有 ID 介于 0(不含)和 10000(包含)之间的用户,如果从数据库查询 ID 不在这个区间的用户,会得到空字符串,所以缓存中缓存的也是空字符串。如果使用 ID=0 去压接口的话,从缓存中查出了空字符串,认为是缓存中没有数据回源查询,其实相当于每次都回源:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @Slf 4j@RestController @RequestMapping ("redis/ct" )public class RedisCtDemo private AtomicInteger atomicInteger = new AtomicInteger(); @Autowired private StringRedisTemplate stringRedisTemplate; @PostConstruct public void init () Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> { log.info("DB QPS : {}" , atomicInteger.getAndSet(0 )); }, 0 , 1 , TimeUnit.SECONDS); } @GetMapping ("wrong" ) public String wrong (@RequestParam("id" ) int id) String key = "user" + id; String data = stringRedisTemplate.opsForValue().get(key); if (StringUtils.isEmpty(data)) { data = getCityFromDb(id); stringRedisTemplate.opsForValue().set(key, data, 30 , TimeUnit.SECONDS); } return data; } private String getCityFromDb (int id) atomicInteger.incrementAndGet(); if (id > 0 && id <= 10000 ) { return "userdata" ; } return "" ; } }
压测后数据库的 QPS 达到了几千:
1 2 3 4 5 6 7 8 9 10 11 2022-09-11 23:23:18.279 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 384 2022-09-11 23:23:19.278 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 2044 2022-09-11 23:23:20.278 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 2656 2022-09-11 23:23:21.279 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 2836 2022-09-11 23:23:22.278 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 3391 2022-09-11 23:23:23.278 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 3907 2022-09-11 23:23:24.278 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 4406 2022-09-11 23:23:25.279 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 4245 2022-09-11 23:23:26.279 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 4524 2022-09-11 23:23:27.278 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 4268 2022-09-11 23:23:28.278 INFO 56864 --- [pool-1-thread-1] c.s.e.d.interfaces.redis.RedisCtDemo : DB QPS : 3920
如果这种漏洞被恶意利用的话,就会对数据库造成很大的性能压力。这就是缓存穿透。
这里需要注意,缓存穿透和缓存击穿的区别:
缓存穿透是指,缓存没有起到压力缓冲的作用; 而缓存击穿是指,缓存失效时瞬时的并发打到数据库。 解决缓存穿透有以下两种方案。
方案一,对于不存在的数据,同样设置一个特殊的 Value 到缓存中,比如当数据库中查出的用户信息为空的时候,设置 NODATA 这样具有特殊含义的字符串到缓存中。这样下次请求缓存的时候还是可以命中缓存,即直接从缓存返回结果,不查询数据库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @GetMapping ("right" )public String right (@RequestParam("id" ) int id) String key = "user" + id; String data = stringRedisTemplate.opsForValue().get(key); if (StringUtils.isEmpty(data)) { data = getCityFromDb(id); if (StringUtils.isNotEmpty(data)) { stringRedisTemplate.opsForValue().set(key, data, 30 , TimeUnit.SECONDS); } else { stringRedisTemplate.opsForValue().set(key, "NODATA" , 30 , TimeUnit.SECONDS); } } return data; }
但,这种方式可能会把大量无效的数据加入缓存中,如果担心大量无效数据占满缓存的话还可以考虑方案二,即使用布隆过滤器做前置过滤。
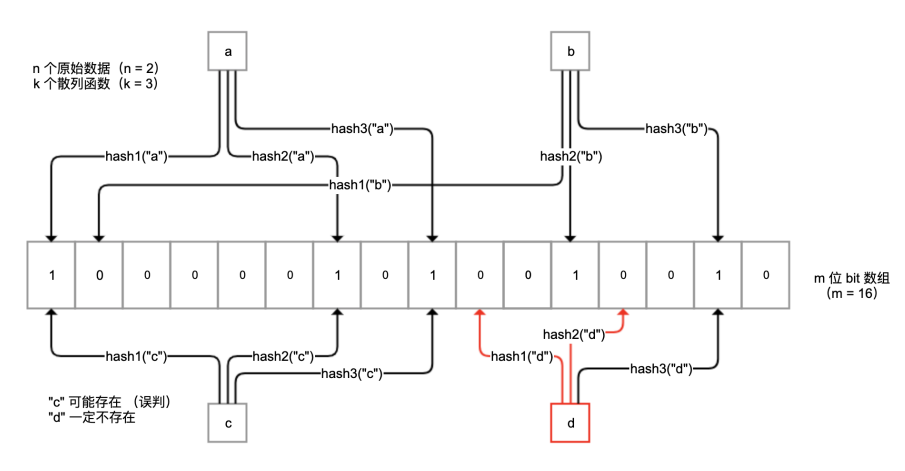
布隆过滤器是一种概率型数据库结构,由一个很长的二进制向量和一系列随机映射函数组成。它的原理是,当一个元素被加入集合时,通过 k 个散列函数将这个元素映射成一个 m 位 bit 数组中的 k 个点,并置为 1。
检索时,我们只要看看这些点是不是都是 1 就(大概)知道集合中有没有它了。如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。
原理如下图所示:
布隆过滤器不保存原始值,空间效率很高,平均每一个元素占用 2.4 字节就可以达到万分之一的误判率。这里的误判率是指,过滤器判断值存在而实际并不存在的概率。我们可以设置布隆过滤器使用更大的存储空间,来得到更小的误判率。
你可以把所有可能的值保存在布隆过滤器中,从缓存读取数据前先过滤一次:
如果布隆过滤器认为值不存在,那么值一定是不存在的,无需查询缓存也无需查询数据库; 对于极小概率的误判请求,才会最终让非法 Key 的请求走到缓存或数据库。 要用上布隆过滤器,我们可以使用 Google 的 Guava 工具包提供的 BloomFilter 类改造一下程序:启动时,初始化一个具有所有有效用户 ID 的、10000 个元素的 BloomFilter,在从缓存查询数据之前调用其 mightContain 方法,来检测用户 ID 是否可能存在;如果布隆过滤器说值不存在,那么一定是不存在的,直接返回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 @Slf 4j@RestController @RequestMapping ("redis/ct/bloom" )public class RedisCtBloomDemo private AtomicInteger atomicInteger = new AtomicInteger(); @Autowired private StringRedisTemplate stringRedisTemplate; private BloomFilter<Integer> bloomFilter; @PostConstruct public void init () bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 10000 , 0.01 ); IntStream.rangeClosed(1 , 10000 ).forEach(bloomFilter::put); Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> { log.info("DB QPS : {}" , atomicInteger.getAndSet(0 )); }, 0 , 1 , TimeUnit.SECONDS); } @GetMapping ("right2" ) public String right2 (@RequestParam("id" ) int id) String data = "" ; if (bloomFilter.mightContain(id)) { String key = "user" + id; data = stringRedisTemplate.opsForValue().get(key); if (StringUtils.isEmpty(data)) { data = getCityFromDb(id); stringRedisTemplate.opsForValue().set(key, data, 30 , TimeUnit.SECONDS); } } return data; } private String getCityFromDb (int id) atomicInteger.incrementAndGet(); if (id > 0 && id <= 10000 ) { return "userdata" ; } return "" ; } }
对于方案二,我们需要同步所有可能存在的值并加入布隆过滤器,这是比较麻烦的地方。如果业务规则明确的话,你也可以考虑直接根据业务规则判断值是否存在。
其实,方案二可以和方案一同时使用,即将布隆过滤器前置,对于误判的情况再保存特殊值到缓存,双重保险避免无效数据查询请求打到数据库。