1. SQL 的执行顺序 常见的select、from、where的顺序:1, from 2, where 3, select
完整的select、from、where、group by、having、order by的顺序:1, from 2, where 3, group by 4,having 5, select 6, order by
2. EXISTS 的使用 EXISTS用来判断查询所得的结果中,是否有满足条件的纪录存在。存在返回 true, 否则返回 false。
1 select * from student where exists (select * from address where zz='郑州' );
3. SELECT CASE WHEN的使用 3.1 语法1 如下所示:
1 2 3 4 5 6 7 CASE WHEN 条件1 THEN action1 WHEN 条件2 THEN action2 WHEN 条件3 THEN action3 ... ELSE actionN END [CASE ]
示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 select case when substr ('20090310' ,5 ,2 ) = '01' then '一月份' when substr ('20090310' ,5 ,2 ) = '02' then '二月份' when substr ('20090310' ,5 ,2 ) = '03' then '三月份' when substr ('20090310' ,5 ,2 ) = '04' then '四月份' else null end month from dual; MONTH 三月份
3.2 语法2 如下所示:
1 2 3 4 5 6 7 CASE SELECTOR WHEN value1 THEN action1 WHEN value2 THEN action2 WHEN value3 THEN action3 ... ELSE actionN END [CASE ]
示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 select case substr ('20200310' , 5 , 2 ) when '01' then '一月份' when '02' then '二月份' when '03' then '三月份' when '04' then '四月份' else null end month from dual;MONTH 三月份
4. 分析函数 分析函数用于计算完成聚集的累计排名、序号等,分析函数为每组记录返回多个行。以下三个分析函数用于计算一个行在一组有序行中的排位,序号从1开始:
示例如下:
1 2 3 4 5 6 7 8 9 10 11 SQL> select * from 成绩; SNO KM SCORE 1 语文 60 1 数学 60 1 英语 60 2 语文 70 2 数学 70 3 英语 80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 SQL> select a.*, row_number() over(order by a.score) rang from 成绩 a; SNO KM SCORE RANG 1 语文 60 1 1 数学 60 2 1 英语 60 3 2 语文 70 4 2 数学 70 5 3 英语 80 6 SQL> select a.*, row_number() over(partition by km order by a.score) rang from 成绩 a; SNO KM SCORE RANG 2 数学 70 1 1 数学 60 2 3 英语 80 1 1 英语 60 2 2 语文 70 1 1 语文 60 2
1 2 3 4 5 6 7 8 9 10 11 SQL> select a.*, rank() over(order by a.score) rang from 成绩 a; SNO KM SCORE RANG 1 语文 60 1 1 数学 60 1 1 英语 60 1 2 语文 70 4 2 数学 70 4 3 英语 80 6
1 2 3 4 5 6 7 8 9 10 11 SQL> select a.*, dense_rank() over(order by a.score) rang from 成绩 a; SNO KM SCORE RANG 1 语文 60 1 1 数学 60 1 1 英语 60 1 2 语文 70 2 2 数学 70 2 3 英语 80 3
5. DECODE 的使用 5.1 语法 在逻辑编程中,经常用到If – Then –Else 进行逻辑判断。在DECODE的语法中,实际上就是这样的逻辑处理过程。它的语法如下:
1 DECODE(value, if1, then1, if2,then2, if3,then3, . . . else )
Value 代表某个表的任何类型的任意列或一个通过计算所得的任何结果。当每个value值被测试,如果value的值为if1,Decode 函数的结果是then1;如果value等于if2,Decode函数结果是then2;等等。事实上,可以给出多个if/then 配对。如果value结果不等于给出的任何配对时,Decode 结果就返回else 。需要注意的是,这里的if、then及else 都可以是函数或计算表达式。
5.2 示例 示例 1 :实现 SEX 如果是 1 则显示 男,如果为 2 则显示 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 SQL> select * from student; ID NAME SEX 1 张 1 2 王 2 3 李 1 SQL> Select name ,decode(sex, '1','男生', '2','女生') sex from student; NAME SEX 张 男生 王 女生 李 男生 SQL> select name, 2 case sex 3 when '1' then '男生' 4 when '2' then '女生' 5 end sex 6 from student; NAME SEX 张 男生 王 女生 李 男生
5.2.1 decode 实现行列转换 如下,由格式1转为格式2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 商品名称 季度 销售额 电视机 01 100 电视机 02 200 电视机 03 300 空调 01 50 空调 02 150 空调 03 180 商品名称 一季度 二季度 三季度 四季度 电视机 100 200 300 0 空调 50 150 180 0
实现方法如下(善用聚合函数):
1 2 3 4 5 6 7 8 select 商品名称, sum (decode (季度, '01' , 销售额, '0' )) 一季度,sum (decode (季度, '02' , 销售额, '0' )) 二季度,sum (decode (季度, '03' , 销售额, '0' )) 三季度,sum (decode (季度, '04' , 销售额, '0' )) 四季度from 销售group by 商品名称;
6. ROWNUM 的使用 常用于分页,作用是对查询结果,输出前若干条记录。
注意:只能与<、<=、between and 连用
6.1 示例 6.1.1 分页示例 数据源表如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 SQL> select * from yggz; BH GZ 1 1000 2 1100 3 900 4 2000 5 1500 6 3000 7 1400 8 1200
需要实现的查出该表中第3行到第5行的数据:
1 2 3 4 5 select a.* from (select yggz.*, rownum rn from yggz ) awhere a.rn >= 3 and a.rn <= 5 ;
7. GROUP BY GROUPING SETS 的使用 7.1 语法 可以用 GROUP BY GROUPING SETS 来进行分组自定义汇总 ,可以应用它来指定你需要的总数组合。==使用GROUPING SETS 的 GROUP BY 子句可以生成一个等效于由多个简单 GROUP BY 子句的 UNION ALL 生成的结果集。==
其格式为:
1 2 3 4 5 6 7 GROUP BY GROUPING SETS ((list1), (list2) ... ) group by list1 union all group by list2 union all ...
这里(list)是圆括号中的一个列序列,这个组合生成一个总数。要增加一个总和,必须增加一个(NULL)分组集。
7.2 示例 对于scott.emp表,如果要查询:各部门sal大于2000的员工,进行汇总,得到各部门的sal总和、以及总共的sal总和。实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 select case when a.deptno is null then '合计' WHEN a.deptno IS NOT NULL AND a.empno IS NULL THEN '小计' ELSE '' || a.deptnoEND deptno,a.empno, a.ename, SUM (a.sal) total_salfrom scott.emp aWHERE a.sal > 2000 group by grouping sets ((a.deptno), (a.deptno, a.empno, a.ename), ());DEPTNO EMPNO ENAME TOTAL_SAL 10 7782 CLARK 2450 10 7839 KING 5000 小计 7450 20 7566 JONES 2975 20 7788 SCOTT 3000 20 7902 FORD 3000 小计 8975 30 7698 BLAKE 2850 小计 2850 合计 19275
8. ROLLUP 的使用 ROLLUP 函数可以同时实现 GROUP BY 与 UNION ALL 两者累加的效果,效果同 group by grouping sets 方法。
比如进行 group by rollup(A, B, C) 操作时,相当于进行了 group by (A, B, C),group by (A, B),group by A 和获取全表合计四步操作。
下面我们将与普通 group by 语句进行对比说明。首先如下是数据源信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 SQL> select * from scott.emp; EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7369 SMITH CLERK 7902 17-12月-80 800 20 7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30 7566 JONES MANAGER 7839 02-4月 -81 2975 20 7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30 7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 7782 CLARK MANAGER 7839 09-6月 -81 2450 10 7788 SCOTT ANALYST 7566 19-4月 -87 3000 20 7839 KING PRESIDENT 17-11月-81 5000 10 7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 7876 ADAMS CLERK 7788 23-5月 -87 1100 20 7900 JAMES CLERK 7698 03-12月-81 950 30 7902 FORD ANALYST 7566 03-12月-81 3000 20 7934 MILLER CLERK 7782 23-1月 -82 1300 10
1. 首先对 emp 进行普通的 group by 分组操作:
1 2 3 4 5 6 7 SQL> select deptno, sum(sal) from scott.emp group by deptno; DEPTNO SUM(SAL) 30 9400 20 10875 10 8750
2. 接着使用 rollup 操作,可以同时求出合计值:
1 2 3 4 5 6 7 8 SQL> select deptno, sum(sal) from scott.emp group by rollup(deptno); DEPTNO SUM(SAL) 10 8750 20 10875 30 9400 29025
上述实现效果同如下语句:
1 2 3 select deptno, sum (sal) from scott.emp group by deptnounion all select null , sum (sal) from scott.emp;
3. 下面再看一下 rollup 两列的情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 SQL> select deptno, empno, sum(sal) from scott.emp group by rollup(deptno, empno); DEPTNO EMPNO SUM(SAL) 10 7782 2450 10 7839 5000 10 7934 1300 10 8750 20 7369 800 20 7566 2975 20 7788 3000 20 7876 1100 20 7902 3000 20 10875 30 7900 950 30 7499 1600 30 7521 1250 30 7654 1250 30 7698 2850 30 7844 1500 30 9400 29025
可以发现除了统计出了所有部门的合计,还统计除了各个部门的小计。效果是不是和 group by grouping sets 很相像呢。我们可以用一般的 group by 实现上述的效果:
1 2 3 4 5 select null , null , sum (sal) from scott.emp union all select deptno, null , sum (sal) from scott.emp group by deptno union all select deptno, empno, sum (sal) from scott.emp group by deptno, empno
9. GROUPING 的使用 介绍完 rollup 函数,就不得不说 grouping 函数了。grouping 函数一般是与 rollup 进行搭配使用的。废话不多说,直接看效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 select deptno, empno, grouping (deptno), grouping (empno), sum (sal)from scott.empgroup by rollup (deptno, empno); DEPTNO EMPNO GROUPING(DEPTNO) GROUPING(EMPNO) SUM(SAL) 10 7782 0 0 2450 10 7839 0 0 5000 10 7934 0 0 1300 10 0 1 8750 20 7369 0 0 800 20 7566 0 0 2975 20 7788 0 0 3000 20 7876 0 0 1100 20 7902 0 0 3000 20 0 1 10875 30 7900 0 0 950 30 7499 0 0 1600 30 7521 0 0 1250 30 7654 0 0 1250 30 7698 0 0 2850 30 7844 0 0 1500 30 0 1 9400 1 1 29025
可以发现原本使用 select deptno, empno, sum(sal) from scott.emp group by rollup(deptno, empno);查询出来的有值的列,在使用了 grouping 函数之后则会返回0,否则就返回 1。
换个说法即是:如果显示“1”表示GROUPING函数对应的列(例如empno字段)是由于ROLLUP函数所产生的空值对应的信息,即对此列进行汇总计算后的结果。如果显示“0”表示此行对应的这列参未与ROLLUP函数分组汇总活动。
10. CUBE 的使用 假设使用 group by cube(A,B,C),首先会对 (A,B,C) 进行 group by ,然后对 (A, B),(A, C) 和 A进行 group by ,然后对 (B, C) 和 B 进行 group by ,然后再对 C 进行 group by。最后对全表进行 group by 操作。可以看出 cube 会列出所有可能的分组。
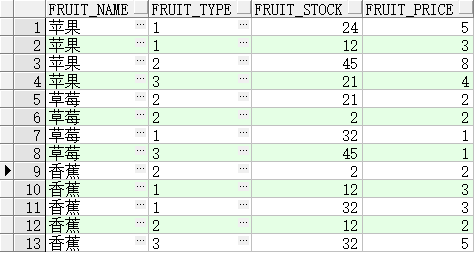
假设现在有表 t_fruit 有如下原始数据:
如下 SQL 使用 cube 函数来统计对应数据:
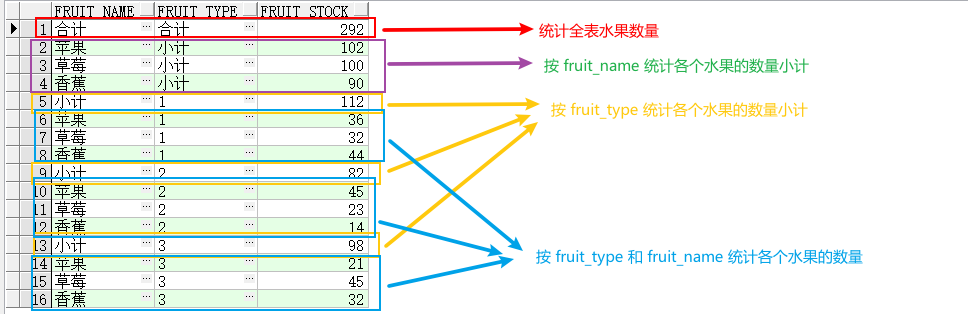
1 2 3 4 5 6 7 8 9 10 11 SELECT CASE WHEN grouping (fruit_name) + grouping (fruit_type) = 2 THEN '合计' WHEN grouping (fruit_name) = 1 THEN '小计' ELSE to_char(fruit_name) END fruit_name, CASE WHEN grouping (fruit_name) + grouping (fruit_type) = 2 THEN '合计' WHEN grouping (fruit_type) = 1 THEN '小计' ELSE to_char(fruit_type) END fruit_type, sum (fruit_stock) fruit_stock FROM t_fruitGROUP BY cube ( fruit_type, fruit_name)
查询结果如下图所示,可以发现 GROUP BY cube ( fruit_type, fruit_name) 可以分为四步操作得到的结果值,分别是 group by fruit_type, fruit_name,group by fruit_name,group by fruit_type 和全表统计。
因此可以拆分为如下四条 SQL:
1 2 3 4 5 6 7 select '合计' fruit_name, '合计' fruit_type,sum (fruit_stock) fruit_stock from t_fruitunion all select to_char(fruit_name) fruit_name, '小计' fruit_type, sum (fruit_stock) fruit_stock from t_fruit group by fruit_nameunion all select '小计' fruit_name, to_char(fruit_type) fruit_type, sum (fruit_stock) fruit_stock from t_fruit group by fruit_typeunion all select to_char(fruit_name) fruit_name, to_char(fruit_type) fruit_type, sum (fruit_stock) fruit_stock from t_fruit group by fruit_type,fruit_name
11. GROUPING_ID 的使用 可以使用GROUPING_ID函数借助HAVING子句对记录进行过滤,将不包含小计或者总计的记录除去 。GROUPING_ID()函数可以接受一列或多列,返回GROUPING 位向量的十进制值 。GROUPING位向量的计算方法是将按照顺序对每一列调用GROUPING 函数的结果组合起来。
1. 首先看一下 grouping_id 的使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 select deptno, empno, grouping (deptno), grouping (empno), sum (sal)from scott.empgroup by rollup (deptno, empno)having grouping_id (empno) < 1 DEPTNO EMPNO GROUPING (DEPTNO) GROUPING (EMPNO) SUM (SAL) 10 7782 0 0 2450 10 7839 0 0 5000 10 7934 0 0 1300 20 7369 0 0 800 20 7566 0 0 2975 20 7788 0 0 3000 20 7876 0 0 1100 20 7902 0 0 3000 30 7900 0 0 950 30 7499 0 0 1600 30 7521 0 0 1250 30 7654 0 0 1250 30 7698 0 0 2850 30 7844 0 0 1500
2. GOURPING位向量计算规则如下所示:
1 2 3 4 5 6 7 非空 非空 0 0 0 非空 空 0 1 1 空 非空 1 0 2 空 空 1 1 3
说明一下,在 group by 或者 rollup 之后, 如果该列的值为空,那么 grouping_id(col) 的值为0,否则就为 1。这点同 grouping 函数是同样的效果的。而 grouping_id(col1, col2) 的值则遵循上述的位向量计算规则。即 grouping(col1) 的值为0,grouping(col2) 的值 1,那么 grouping(col1, col2) 的值即为1。其他同理。
12. WITH AS 语句 with as 的语法如下,其相当创建了一个临时表:
1 2 with 临时数据集名称 as (select ....)select ...
当执行 sql 查询时需要对有规律的一批数据进行分析处理而又不想将这批数据存入实体表时,我们可以使用with关键字临时构建一个虚拟的数据集,以便对其进行与实体表相似的 sql 操作,如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 create table student ( sno number (8 ) primary key , sname varchar2(50 ) ); insert into student values (120 , 'aa' );insert into student values (1630 , 'bb' );insert into student values (1200 , 'cc' );insert into student values (999 , 'dd' );with tab1 as ( select * from student where sno > 1000 ) select * from tab1;
上述的 with as 语句的执行结果如下所示:
1 2 3 4 5 6 7 8 9 SQL> with tab1 as( 2 select * from student where sno > 1000 3 ) 4 select * from tab1; SNO SNAME 1630 bb 1200 cc