1. Solr 简介
Solr 是一个独立的企业级搜索应用服务器,它对外提供类似于 web-service 的 API接口。用户可以通过 http 请求,向搜索引擎服务器提交一定格式的 XML 文件,生成索引。也可以通过 Http Get 操作提出查找请求,并得到 XML 或者 JSON 格式的返回结果。本文以使用 solr 全文搜索服务来实现站内搜索的功能。
2. Solr 下载安装
由于本人是在 Windows 下使用 Solr 全文搜索服务器的,因此这里仅介绍 Solr 在 Windows 下的安装以及配置等操作。首先需要前往官网下载 Solr,我下载的版本是 solr 6.2.0,具体的下载位置可以访问该网址。具体的下载位置如下所示。解压安装的时候一直 next 即可。
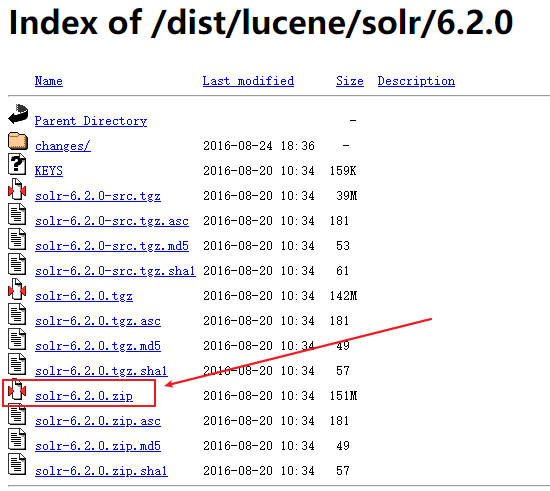
需要注意的是,Solr 与 JDK 之间在版本上是存在对应关系的,比如我本人所使用的 solr 6.2.0 仅支持 JDK1.8 及以上的版本,不然在启动 Solr 服务器的时候是会报错的,这一点需要格外注意。solr 、jdk 和 tomcat 之间版本的对应关系可以参考该文章,这里不再赘述。
3. 运行 Solr
solr 的运行有两种方式,一种是集群方式一种是单机方式,其对应的命令如下所示:
1 | ## 集群方式 |
下面我们就以单机的方式来启动 solr 全文搜索服务器。首先需要进入 solr 的 bin 目录下,然后在命令行窗口中输入如下命令用于启动 Solr 服务器:
1 | solr start |
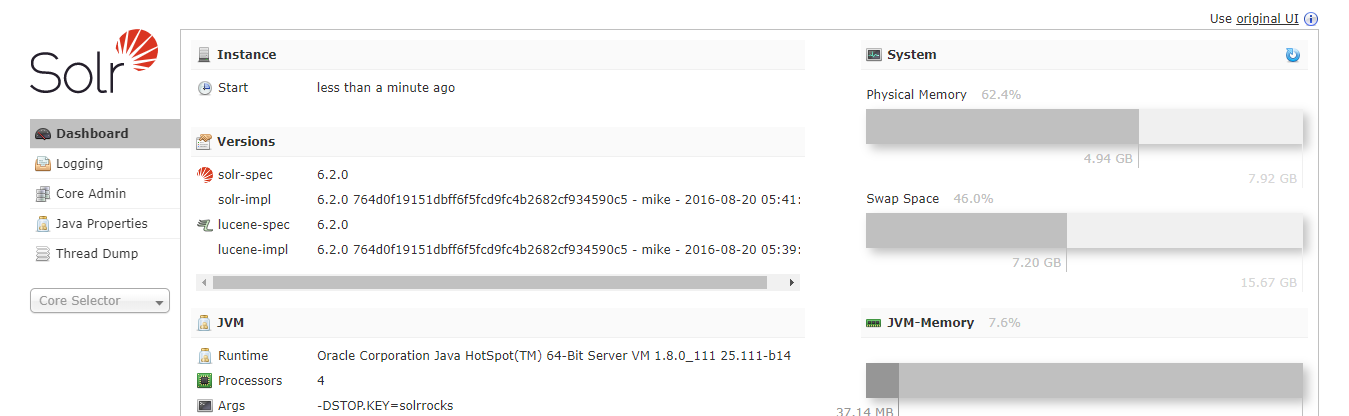
启动完成之后即可以在浏览器使用 ‘http://localhost:8983/solr/#/' 访问 Solr 全文搜索服务器的后台管理页面了,具体如下所示:
另外,solr 服务器有许多常用的命令,具体如下所示:
1 | ## 单机版启动solr服务,端口号可以不指明 |
4. core 实例创建
4.1 core 简介
简单说 core 就是 solr 的一个实例,一个 solr 服务下可以有多个 core,每个 core 下都有自己的索引库和与之相应的配置文件,所以在操作solr 创建索引之前要创建一个 core,因为索引都存在 core 下面。
4.2 core 创建
core 的创建同样存在两种方式,一种是通过命令的方式,一种则是在 solr 的后台管理页面进行创建。
1)命令方式:首先我们可以在命令行中运行如下命令来创建名为 cqa 的 core 实例:
1 | solr create -c cqa |
创建完成之后,则可以在 solr-6.2.0/server/solr 下生成 cqa 的目录文件,具体如下图所示:
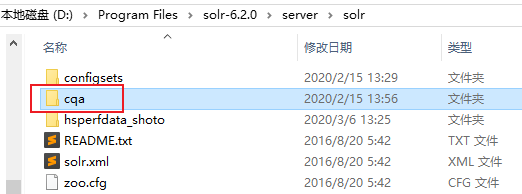
后续我们需要进行索引文件和中文分词器的配置,具体的配置文件在 cqa/conf 目录下,关于配置后面我们在进行介绍。
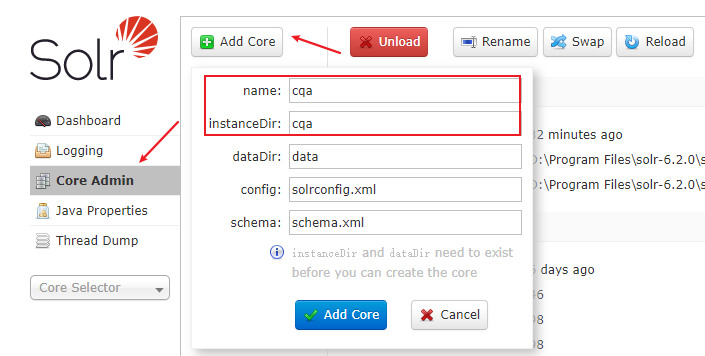
2)界面方式:按照下图的指示,可以直接在 solr 的后台管理界面上进行 core 实例的创建。
5. 中文分词器配置
首先需要明白分词的概念,比如我们在使用百度搜索 “你好” 的时候,那么在进行查询分词的时候可能会分为 “你”,“好” 和 “你好”,然后在搜索包含这三个关键词的文档。当然这是在使用的了中文分词器的情况下,但是如果在没有使用中文分词器的时候,“你好” 仅会被分词为 “你” 和 “好”,显然这样是满足不了我们具体的需求的。由于 solr 默认仅支持部分中文分词,因此需要我们自己去配置第三方中文分词器。
1)首先我们需要在自定义的 core 实例 cqa/conf 目录下的 managed-schema 文件中进行如下中文分词器的配置。需要配置索引分词器和查询分词器,两者的实现效果是不一样的。索引分词器的分词粒度更细,比如可以对将 “你好” 进行 “你”、“好” 和 “你好” 的分词,以此我们在输入“你好”进行查询的时候,我们可以查找更多数据。而查询分词器的分词粒度较粗而且更为只能,比如使用查询分词器的时候,“你好” 只能被分词为 “你好”,以此我们可以以关键字“你好”去查询,而不会以关键“你”或“好”去查询,这就是查询分词器的好处。
1 | <fieldType name="text_ik" class="solr.TextField"> |
另外,这里需要说明的是 IKTokenizerFactory 引用的是 Ik-analyzer 的源码类文件,后续我们需要在 solr 引用包含该文件的 jar 包。
除了上述的配置之外,我们还需要进行如下配置。由于我们的需求是可以通过站内搜索问题的标题(title)和问题的描述内容(content),因此我们需要对两者进行索引。
1 | <!--对问题标题建立索引--> |
2)然后我们需要在 solr-6.2.0 下创建 ext/ikanalyzer 目录,然后在该目录下存放 ikanalyzer-6.2.0.jar,该 jar 即为中文分词器的源码 jar,以此上面的配置便可以使用该 jar 中的类文件。ikanalyzer-6.2.0.jar 该 jar 包可以访问该链接进行下载 https://pan.baidu.com/s/1JIQBFQ-wCN6PLwiBkGVB2g,提取码为 zgey。
接着我们还需要在 solr-6.2.0\server\solr\cqa\conf\solrconfig.xml 中指明该 jar 包的位置,具体配置如下所示:
1 | <lib dir="${solr.install.dir:../../../..}/ext/ikanalyzer" regex=".*\.jar" /> |
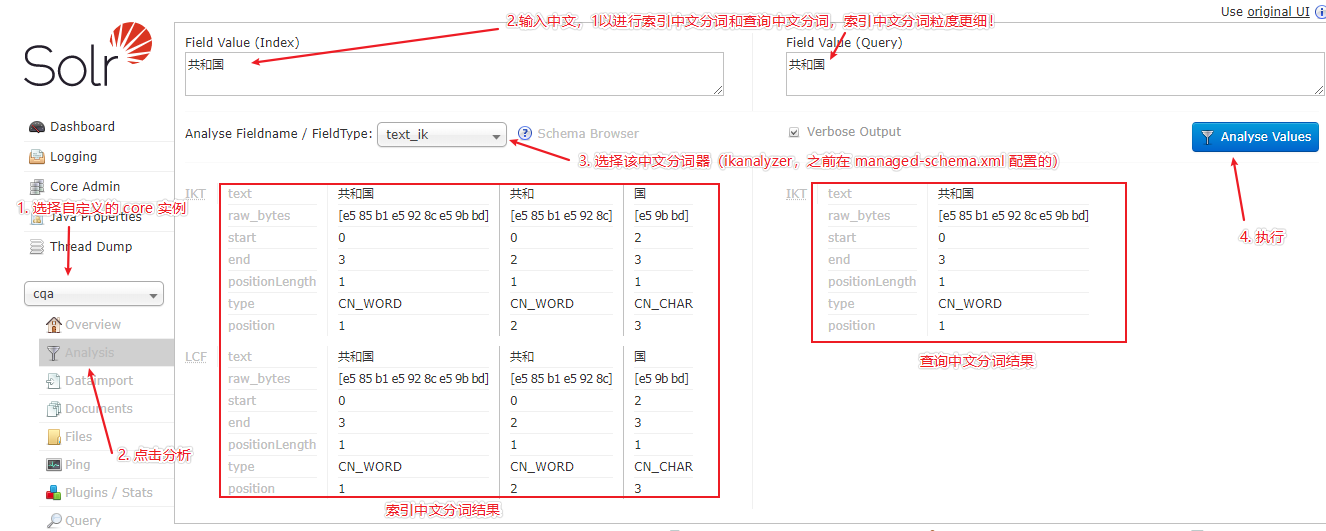
3)在配置完成中文分词器之后,并进行下述数据库数据的导入之后,我们可以验证中文分词器是否配置成功,具体验证步骤如下图所示:
6. 数据库数据导入
由于我们需要对问题标题和问题描述建立索引,因为我们需要将问题的数据从数据库中导入到 solr 服务器中,以此让 solr 服务器进行索引的创建。下面开始进行相关的配置。
1)首先需要引入 mysql 的 jar 包,需要在 solr-6.2.0\ext 目录下创建 mysql 目录,然后将 mysql-connector-java-8.0.12.jar(根据自身使用的 mysql 版本来定)存放进去。
接着在 solr-6.2.0\server\solr\cqa\conf\solrconfig.xml 中指明该 jar 包的位置,具体配置如下所示:
1 | <lib dir="${solr.install.dir:../../../..}/ext/mysql" regex=".*\.jar" /> |
2)然后需在 solr-6.2.0\server\solr\cqa\conf 目录创建 solr-data-config.xml 配置文件,用于配置连接 mysql 数据库的信息,具体内容如下所示:
1 | <dataConfig> |
接着需要同样需要在 solr-6.2.0\server\solr\cqa\conf\solrconfig.xml 中指明该 xml 配置文件的位置,具体配置内容如下所示:
1 | <requestHandler name="/dataimport" class="solr.DataImportHandler"> |
然后按下图所示,完成数据的导入: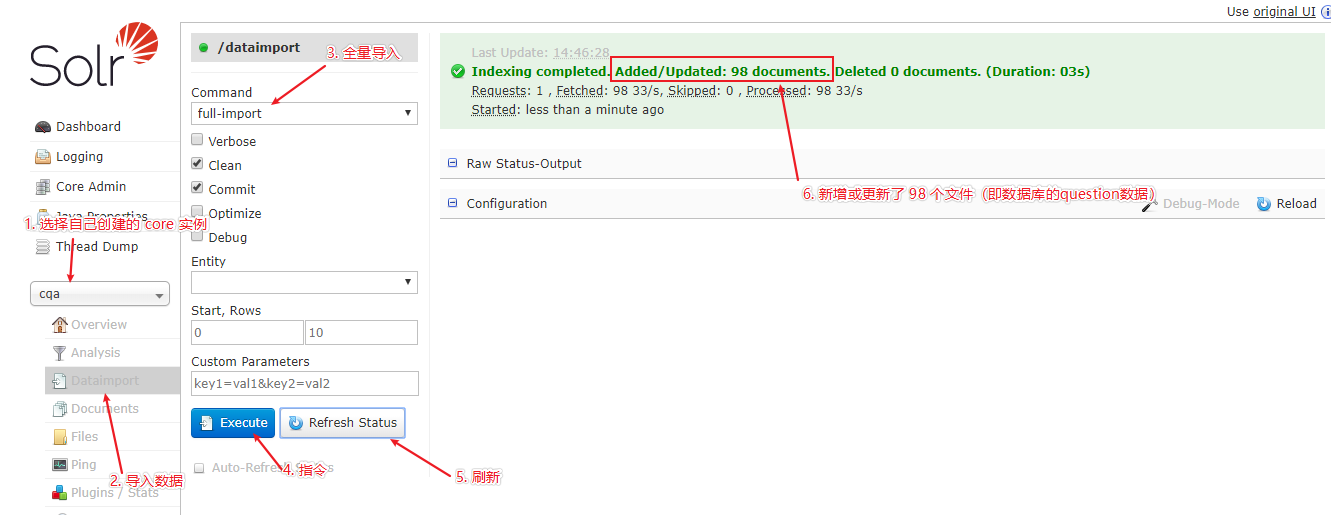
7. 运行 core 实例
在 solr 配置完毕之后,下面就需要运行 core 实例,验证其是否能够正确返回我们的数据,具体验证步骤和执行结果如下所示:
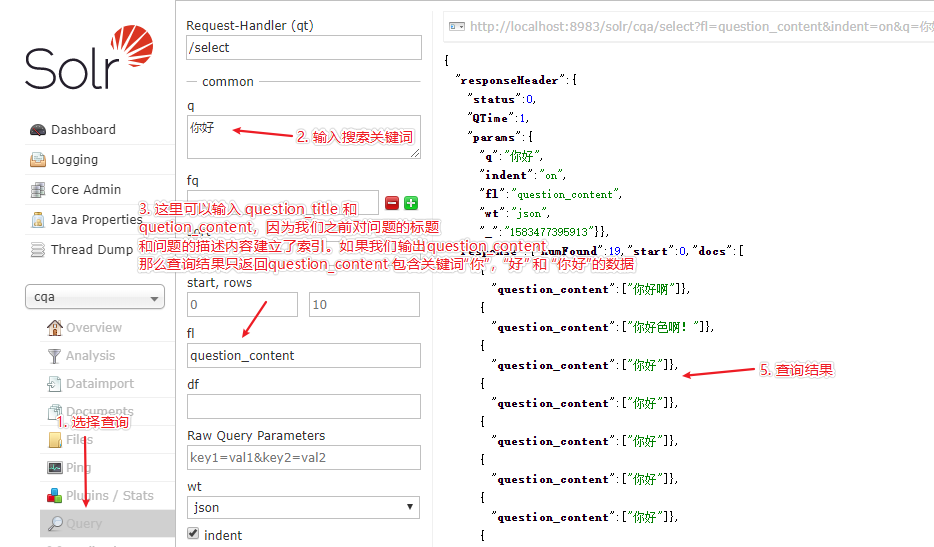
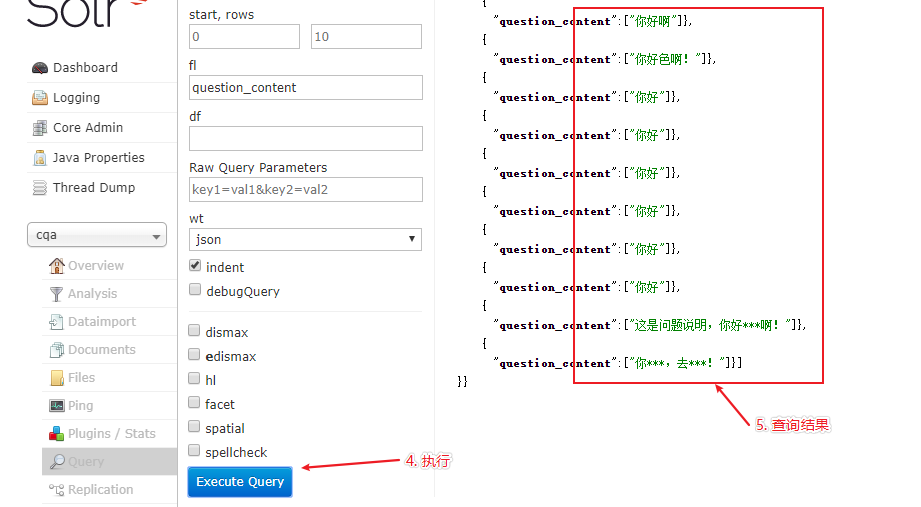
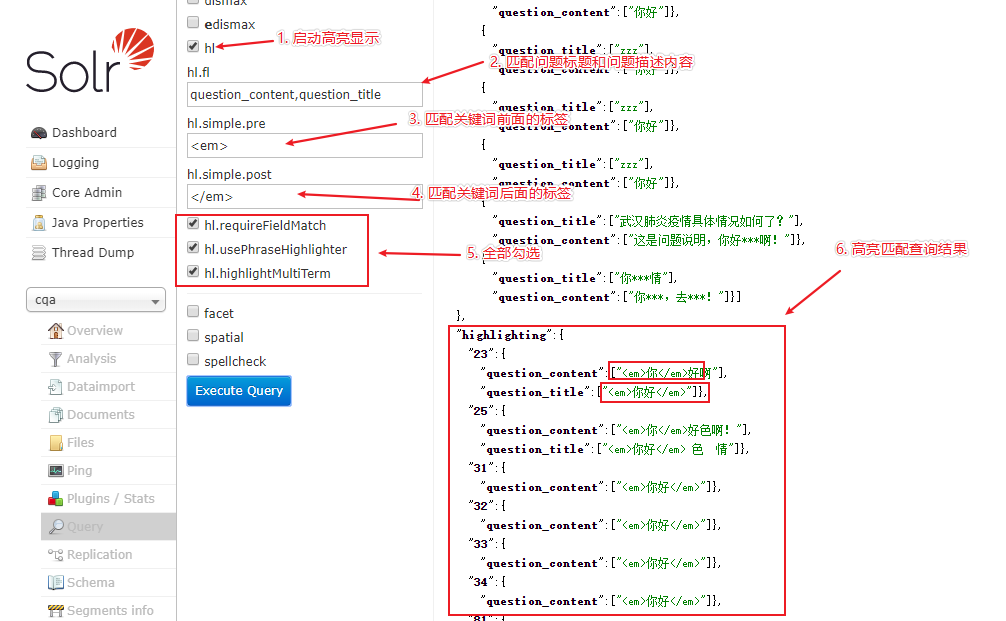
另外,我们也可以对查询出来匹配的关键词进行高亮显示,具体执行步骤和执行结果如下所示:
8. 整合 Java 项目
与 Redis 类似,Solr 全文搜索服务器同样可以与 Java 进行整合,下面我们具体来介绍一下 solr 是如何与 Java (SpringBoot 项目)进行整合的吧。
8.1 导入依赖
1 | <!-- solr 相关依赖导入--> |
8.2 Service 层实现
如下代码所示,是与 Java 调用 solr 全文搜索服务器的关键代码:
1 |
|
高亮查询结果在前端的显示结果如下所示: