1. 介绍
PySpider 是一个基于 Python 的爬虫框架,也就是使用该框架需要懂得一定的 Python 语言。关于 PySpider 的中文文档可以访问 pyspider中文文档。
我们可以在 PySpider 提供的界面上编写和运行 Python 脚本,同时也支持 MySQL, MongoDB, Redis, SQLite, Elasticsearch各种数据库引擎。本文档将实现将 v2ex 中爬取的数据存放在 MySQL 数据库中。下面就先开始从 PySpider 的环境安装开始吧。
2. 环境安装
下面介绍一下在 Windows 10 中 PySpider 的安装,当然由于 PySpider 是基于 Python 的,所以也自然需要先安装 Python,这里我们选择 Python 2.7 32bit。在安装 PySpider 的安装过程中还会涉及到许多插件的安装以及配置的修改。下面就开始一步一步的安装 PySpider 吧。
2.1 Python 2.7 安装
首先是到官网中下载对应的 Python 安装包,具体位置如下所示:
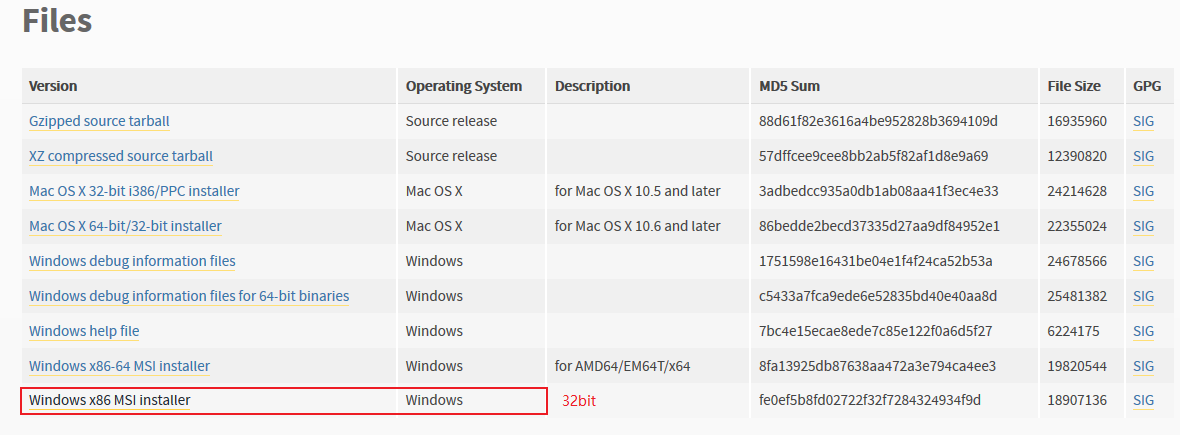
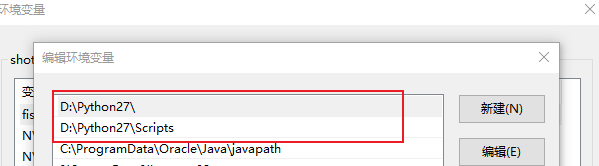
然后运行一直 next 即可,然后就是进行环境变量的配置。在 path 中添加如下环境变量,具体路径根据具体情况而定。
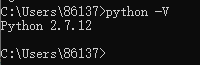
打开命令行窗口,输入 ‘python -V’,如果可以打印版本号,说明 Python 已经安装成功。如下所示:
2.2 PySpider 安装
pip 安装:pip 是 Python 包管理工具,该工具提供了对Python 包的查找、下载、安装、卸载的功能。Python 2.7.9 + 或 Python 3.4+ 以上版本都自带 pip 工具。我们可以通过如下命令判断 pip 是否已经安装。
1
pip -V
如果没有进行 pip 的安装,可以通过如下命令进行安装。用哪个版本的 Python 运行安装脚本,pip 就被关联到哪个版本。
1
2$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py # 下载安装脚本
$ sudo python get-pip.py # 运行安装脚本pycURL 安装:一般情况下在安装 python 的时候会自动安装好 pycURL。如果没有,那么首先需要到该网站中下载与 python 对应版本的安装文件,具体如下所示。这里我们选择 2.7 32bit 的版本。
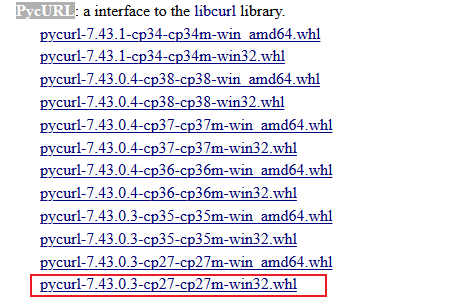
然后在 cmd 窗口中输入如下命令完成 pycURL 的安装:
1
2
3pip install 文件全路径
比如:
pip install D:\pycurl-7.43.0.3-cp27-cp27m-win32.whllxml 安装:同安装 pycURL 一样,我们需要安装 lxml。先到该网站中下载与 python 对应版本的安装文件,具体如下所示。这里我们同样选择 2.7 32bit 的版本。
VCForPython27.msi 和 mysql-connector-c-6.0.2-winx64.msi 安装,windows 直接双击运行即可。
mysql-python 安装:安装的具体命令如下所示:
1
pip install mysql-python
phantomjs 安装:从官网中下载安装包,解压后将phantomjs.exe文件放到python根目录。
pyspider 安装:如下所示,我们可以使用如下命令安装 pyspider,具体命令如下:
1
pip install pyspider
安装的时候,发生了如下的错误:
1
Deprecated option 'domaincontroller': use 'http_authenticator.domain_controller' instead.
解决的方法是找到 pyspider 的安装位置(’Python27\Lib\site-packages\pyspider\webui\webdav.py’),修改文件的第 209 行即可。即把’’domaincontroller’: NeedAuthController(app),’ 改为如下语句:
1
2
3'http_authenticator':{
'HTTPAuthenticator':NeedAuthController(app),
},修改完成之后,还发生了如下的错误。本人目前在 Github 项目中的 issues 中或者在网上并没有找到相关的解决办法
1
ImportError: cannot import name DispatcherMiddleware
根据报错信息,修改了 ‘Python27\Lib\site-packages\pyspider\webui\app.py’ 该文件,将发生错误的地方使用 try catch 进行捕获,这并不会影响 PySpider 框架的运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14try:
from .webdav import dav_app
except ImportError as e:
logger.warning('WebDav interface not enabled: %r', e)
dav_app = None
# 第 63 行的位置
if dav_app:
try:
from werkzeug.wsgi import DispatcherMiddleware
application = DispatcherMiddleware(application, {
'/dav': dav_app
})
except ImportError as e:
logger.warning('')至此,PySpider 框架的安装终于完成了,我们可以在命令行窗口中输入 ‘pyspider all’ 运行 PySpider 框架,并在浏览器上输入如下 URL 访问 PySpider:
1
https://localhost:5000
访问后,浏览器会显示如下界面,下面我们开始介绍 PySpider 框架的使用。
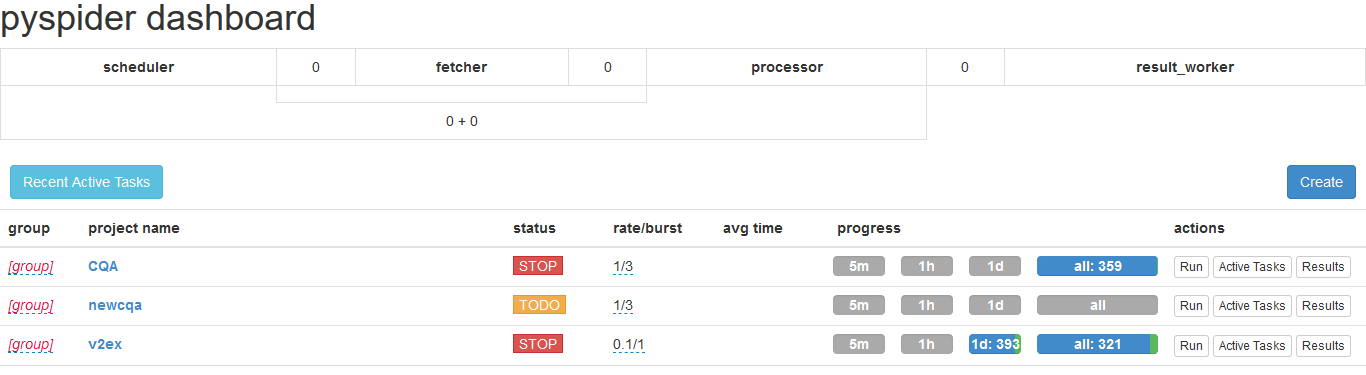
3. PySpider 使用
3.1 项目创建
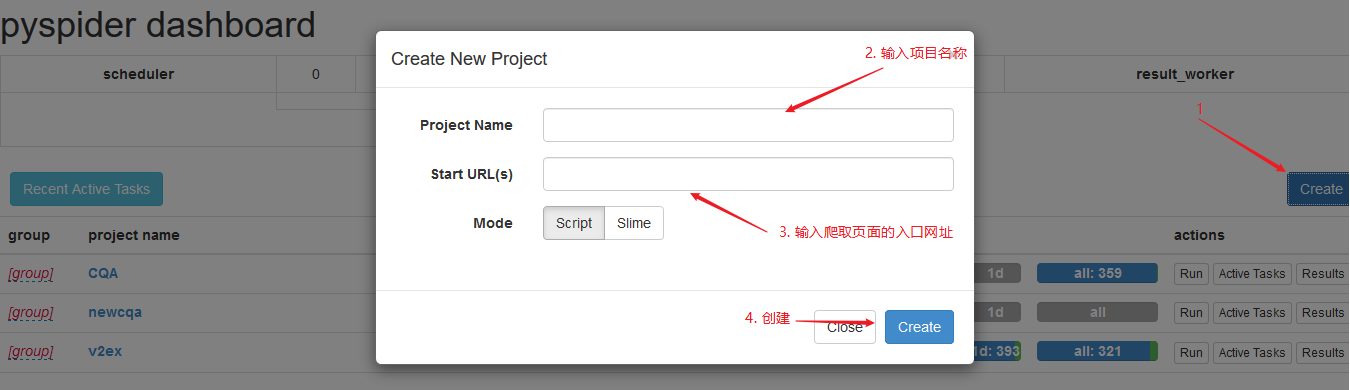
如下所示,进行爬虫项目的创建,具体步骤如下所示:
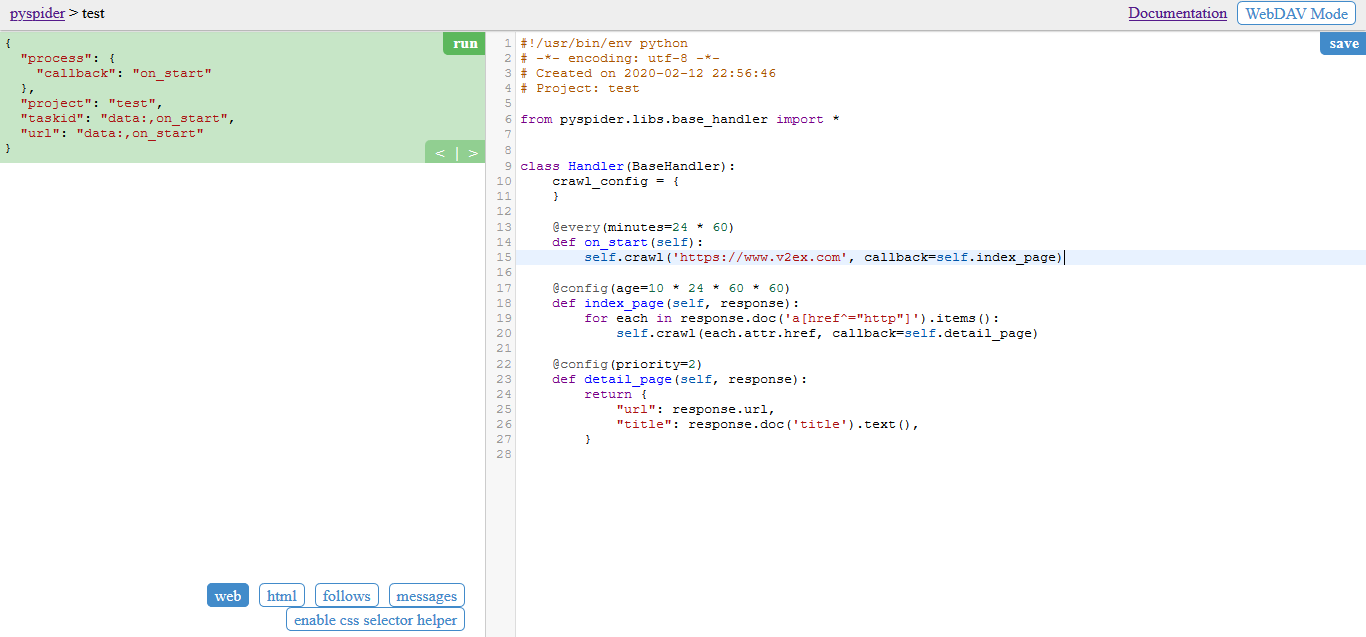
项目创建完成之后,会进入如下页面,左侧是查看运行结果的地方,右侧则是编写具体的 python 脚本位置。
3.2 PySpider 语法
3.2.1 PySpider 原生示例
查看上图,右侧是有默认生成的脚本代码。对于代码的含义具体如下的注释说明:
1 | # 告诉操作系统到 usr/bin/env 里查找 python 的安装路径,再调用对应路径下的解释器程序完成操作 |
3.2.2 PyQuery 之 Response
PyQuery 库是 JQuery 的 Python 实现,能够以 JQuery 的语法来操作解析 HTML 文档,易用性和解析速度都很好,和它差不多的还有BeautifulSoup,都是用来解析的。
在 PySpider 的使用中,Response 对象的使用是比较频繁的。PySpider 的官网就有关于 Response 的使用。下面我们仅列出 Response 常用的几个方法,具体如下所示:
| 方法/属性 | 描述 |
|---|---|
| doc | Html 查找 PyQuery 对象 |
| url | 对应链接 |
| text | 文本 |
| header | 返回的header |
| cookies | 下发cookie |
3.2.3 CSS 选择器
使用 PySpider 编写 Python 爬虫脚本的时候,需要使用到 CSS 选择器,CSS 选择器的作用即是用于解析页面上的 html 元素,关于 CSS 选择器的参考资料可以访问该网站。 下面我罗列了常用 CSS 选择器语法,具体如下所示:
| 选择器 | 描述 |
|---|---|
| .class | class=“class” |
| #id | <p id=”id”> |
| div.inner | <div class=”inner”> |
| a[href^=“http://”] | 带http开头href的a元素 |
| p div | p元素下的div元素(不必父子) |
| p>div>span | p元素下的div元素下的span |
| [target=_blank] | Target=_blank |
3.3 爬虫实例
下面我们将爬取 v2ex 网站中帖子的标题和内容,爬虫的代码具体如下所示,具体的爬虫实现需要参考爬取的网页 HTML 结构:
1 | #!/usr/bin/env python |
下面我们结合这 v2ex 网站来分析一下上述脚本的具体作用,查看如下代码:
1 |
|
‘a[href^=”https://v2ex.com/?tab="]' 表示爬取页面的第二个入口,即 v2ex 主页上的一个标签栏,具体如下图所示:
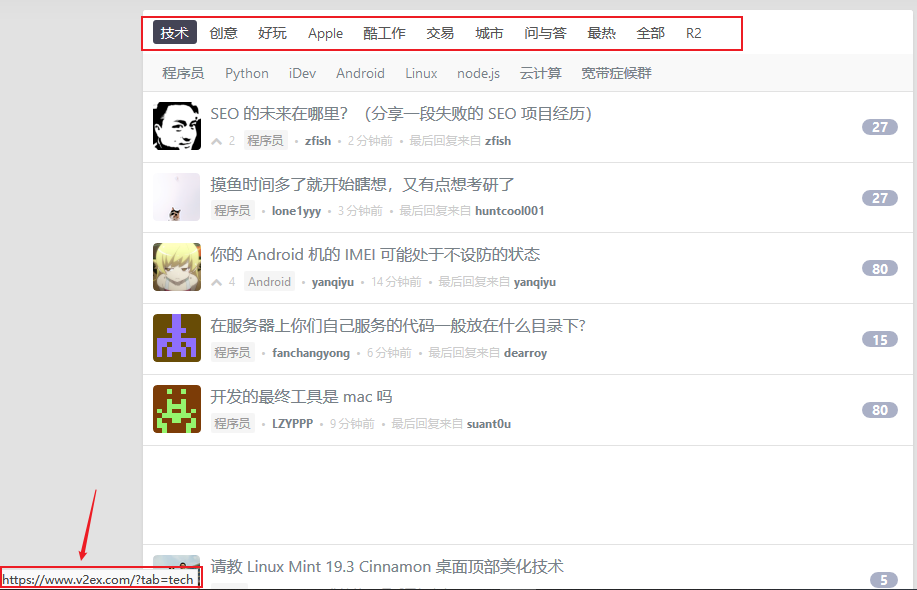
观察如下代码,同上面的一样,’a[href^=”https://v2ex.com/go/"]'是爬虫的第三个入口,以 go 开头。具体如下图所示:
1 |
|
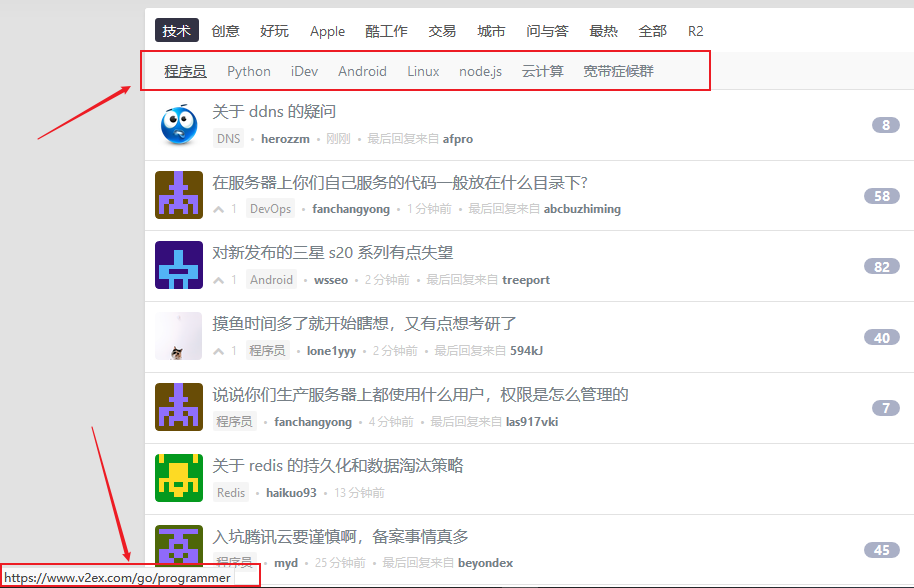
观察如下代码,’a[href^=”https://v2ex.com/t/"]' 为第四个入口,这里已经到达具体的文章链接了,如下图所示。对于文章链接我们这里需要将形如 #reply12 的后缀去掉,然后在调用 detail_page 方法获取我们需要的数据,即帖子的标题和内容。
1 |
|
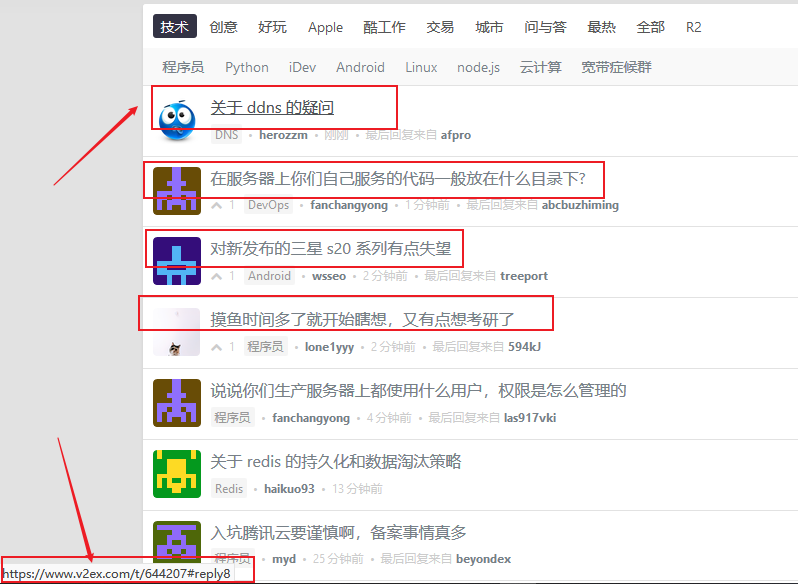
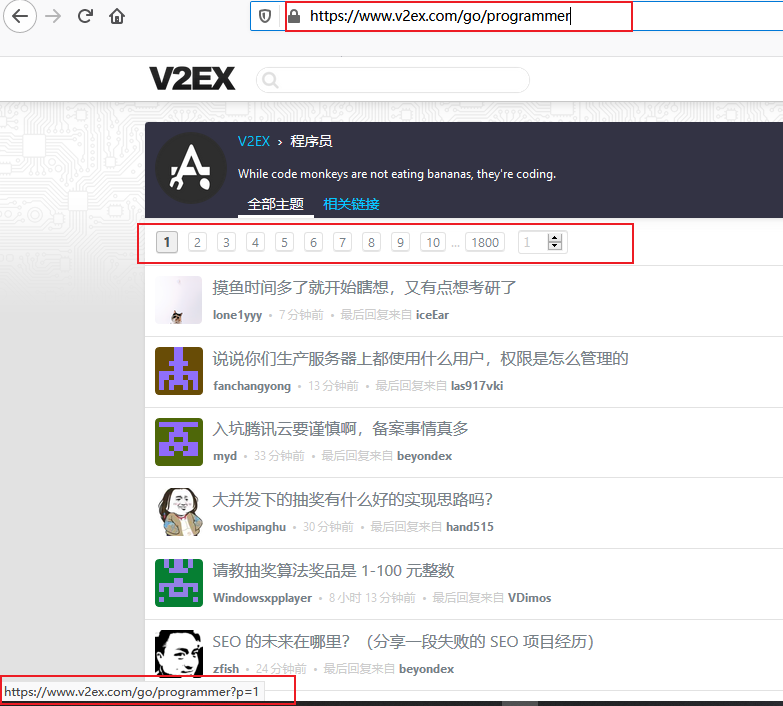
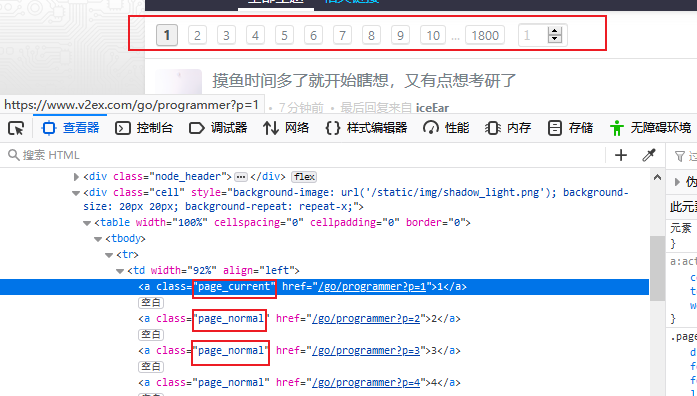
观察上面涉及翻页然后回调本身的方法的代码,这里涉及到翻页的操作,具体体现如下图所示。每一页都是由 p = 页码 来表示。要进行具体的翻页操作,自然需要获取翻页的链接。我们可以查看页面元素,如图2所示。我们发现翻页链接都是存放在 a 标签 calss 名为 page_normal 下的,因此我们可以通过 ‘response.doc(‘a.page_normal’)’ 来获取。
观察如下代码,这是爬虫的最后一步,在该方法中可以获取帖子的标题和内容。
1 |
|
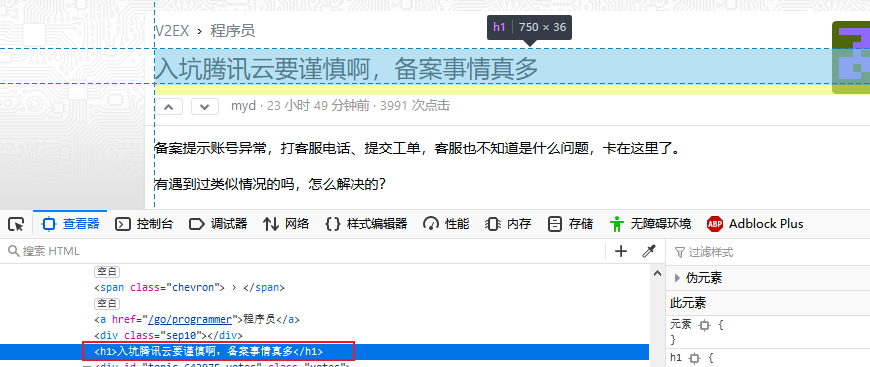
其中我们可以通过 response.doc(‘h1’).text() 获取帖子的标题,这需要根据具体的页面元素而定。v2ex 的页面定义如下图所示:
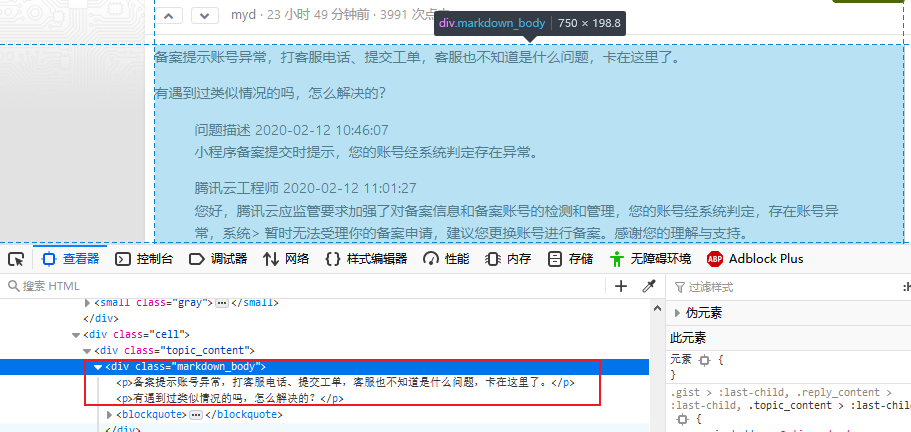
同理我们通过 response.doc(“div.markdown_body”).html() 获取帖子的内容,帖子的内容具体即存放在 class 为 markdown_body 的 div 下中,具体如下图所示:
3.4 数据爬取
在 python 爬虫脚本编写完成之后,需要进行界面的操作,以此进行数据的爬取。在 PySpider 界面操作的时候,可以分为手动点击数据爬取和自动的爬取。下面就讲解一下相关的内容。
3.4.1 手动操作
如下所示,点击 run 之后,界面下方会出现 follows 的红点标识:
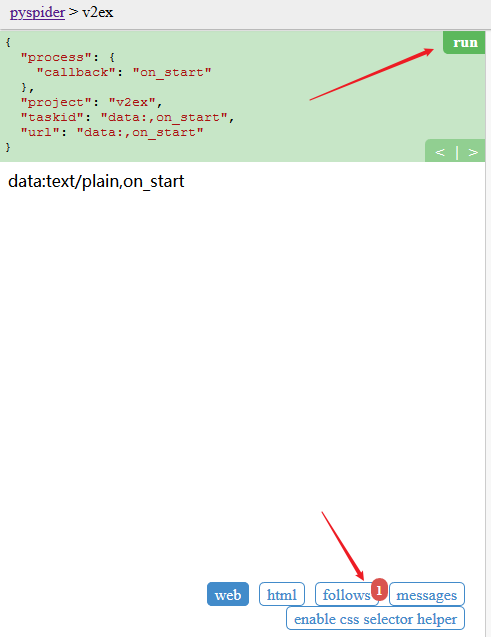
接着点击 follows ,然后点击执行,具体如下图所示:
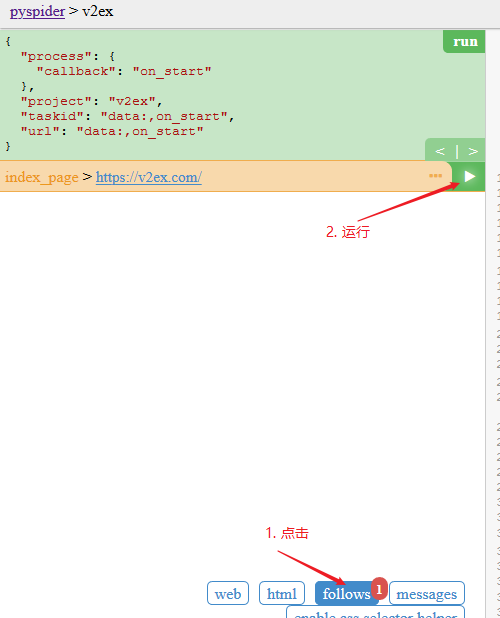
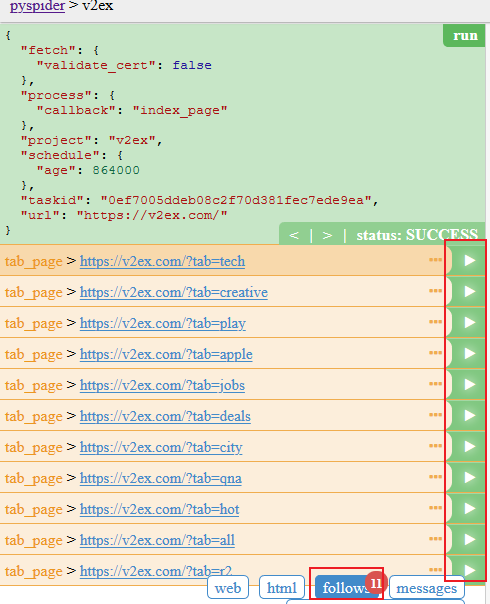
如下图所示,页面显示的内容是根据我们编写的爬虫脚本代码进行的,当进入的具体的帖子页面的时候,则完成数据的入库操作。
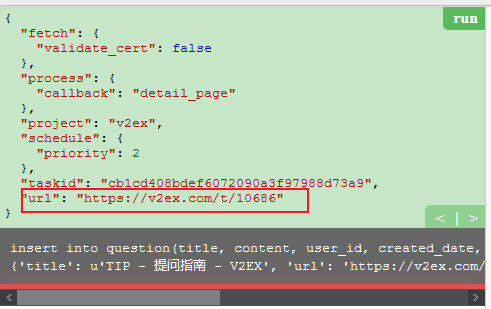
如下图所示,数据完成入库操作,打印出执行的 SQL 语句。
3.4.2 自动操作
当然我们也可以让 PySpider 进行数据的自动爬取,如下图所示,更改执行状态,然后点击 run 进行执行,并点击 Active Tasks 查看具体的执行过程。

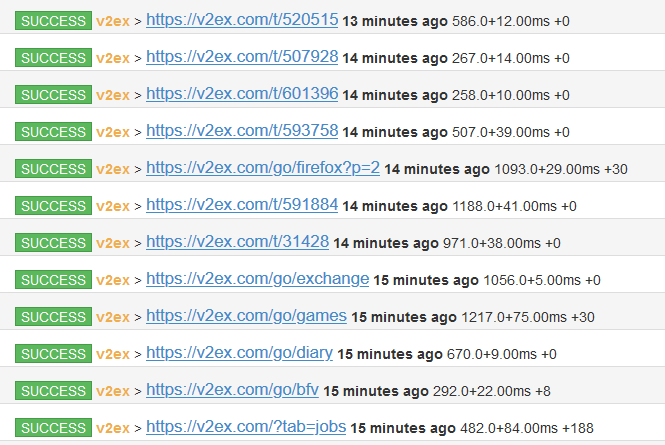
我们还可以更改爬取的频率,如下图所示,我将频率更改为每秒钟 0.1 次:
